7 相関のグラフ
記述統計で見たように、多くの場合、我々が関心を持つのは1つの変数の分布(だけ)というより、複数の変数の間の関係ではないかと思います。今回はそのような関係を可視化する方法を学びます。
7.1 散布図
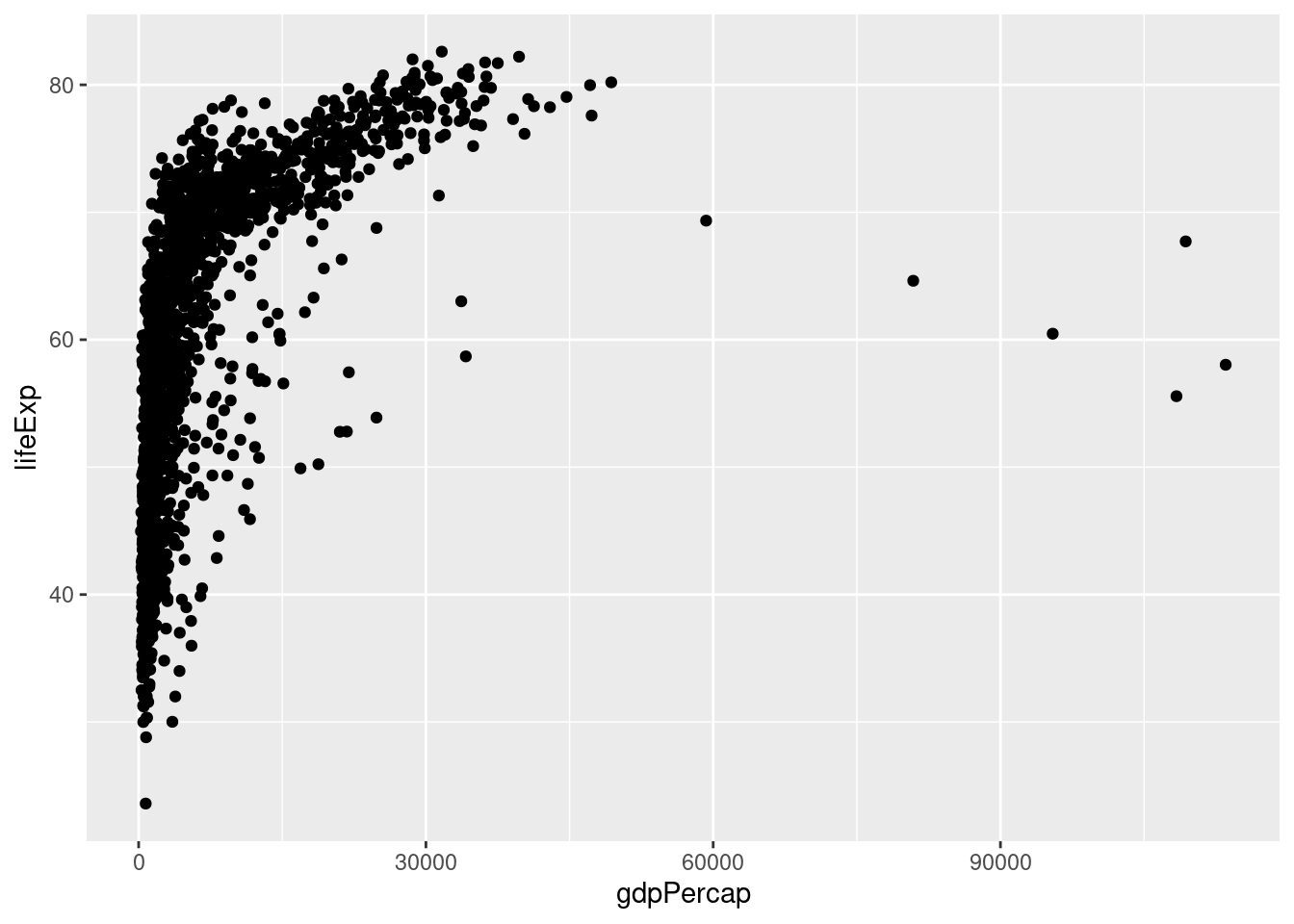
連続変数同士の関係を可視化するグラフを散布図 (scatter plot) と呼びます。ヒストグラムなどを作図するときとほとんど同じようにできることが分かるかと思います。
geom_point()で散布図を作成し、aes()の中でx軸とy軸に使う変数を指定します。
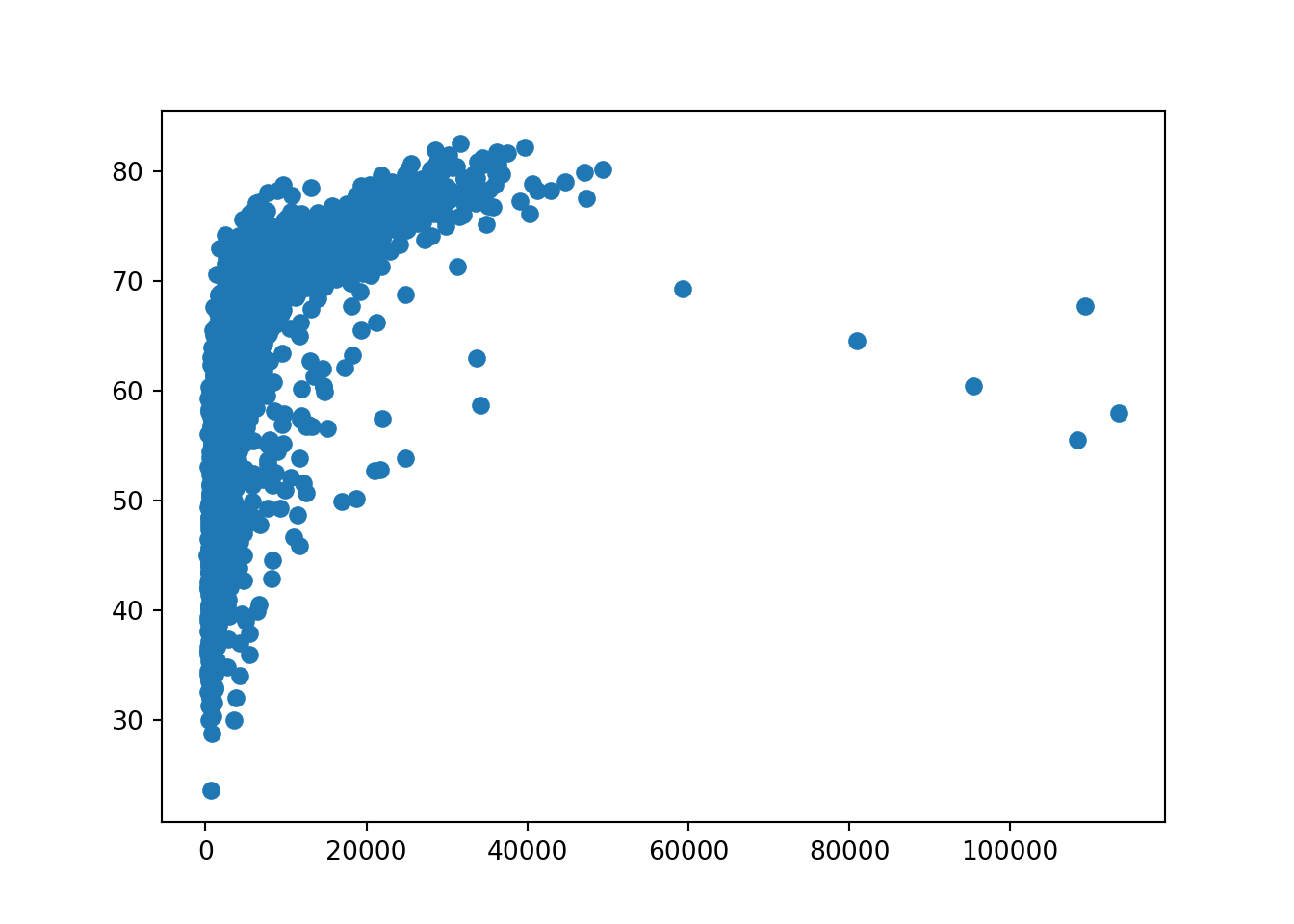
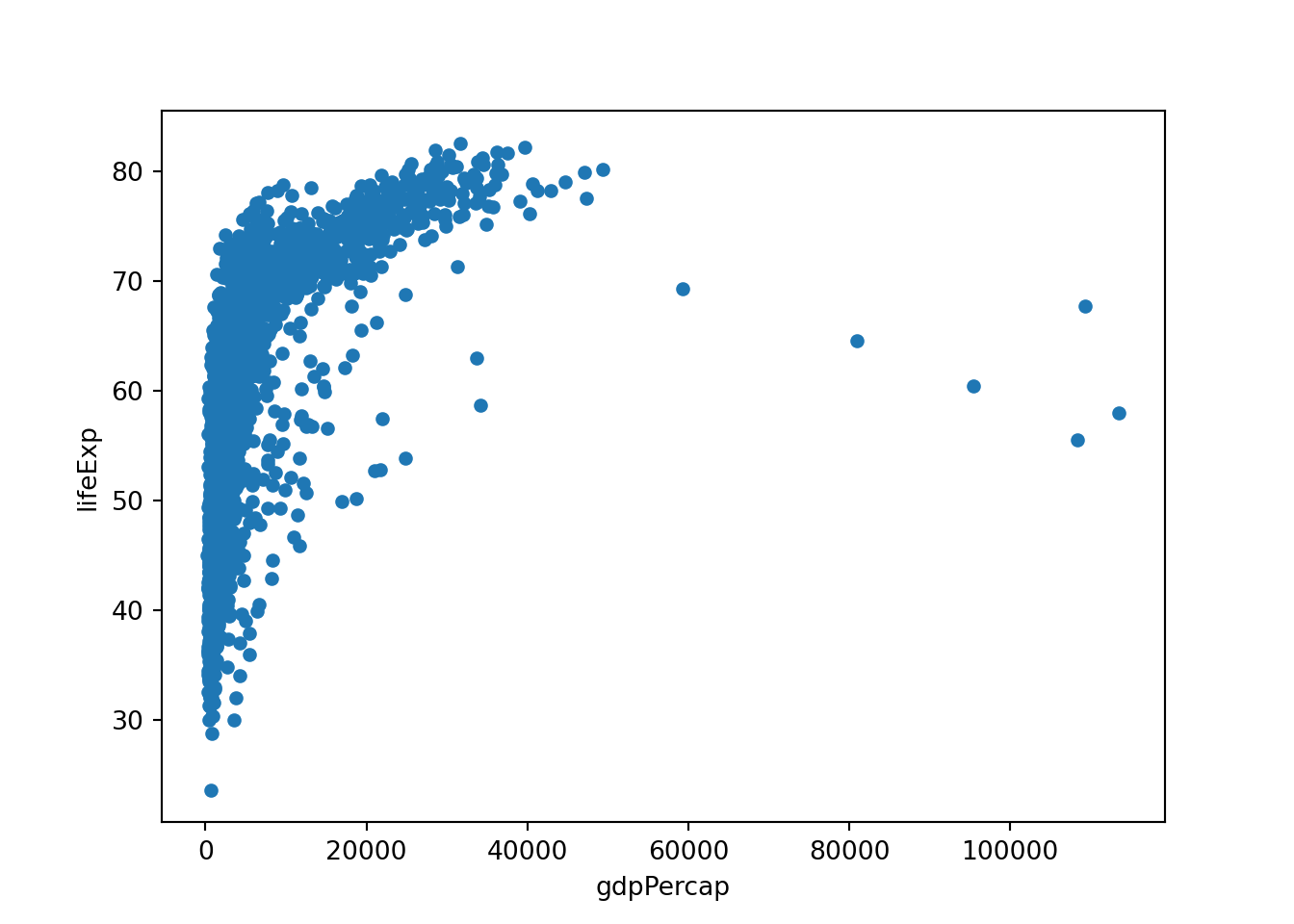
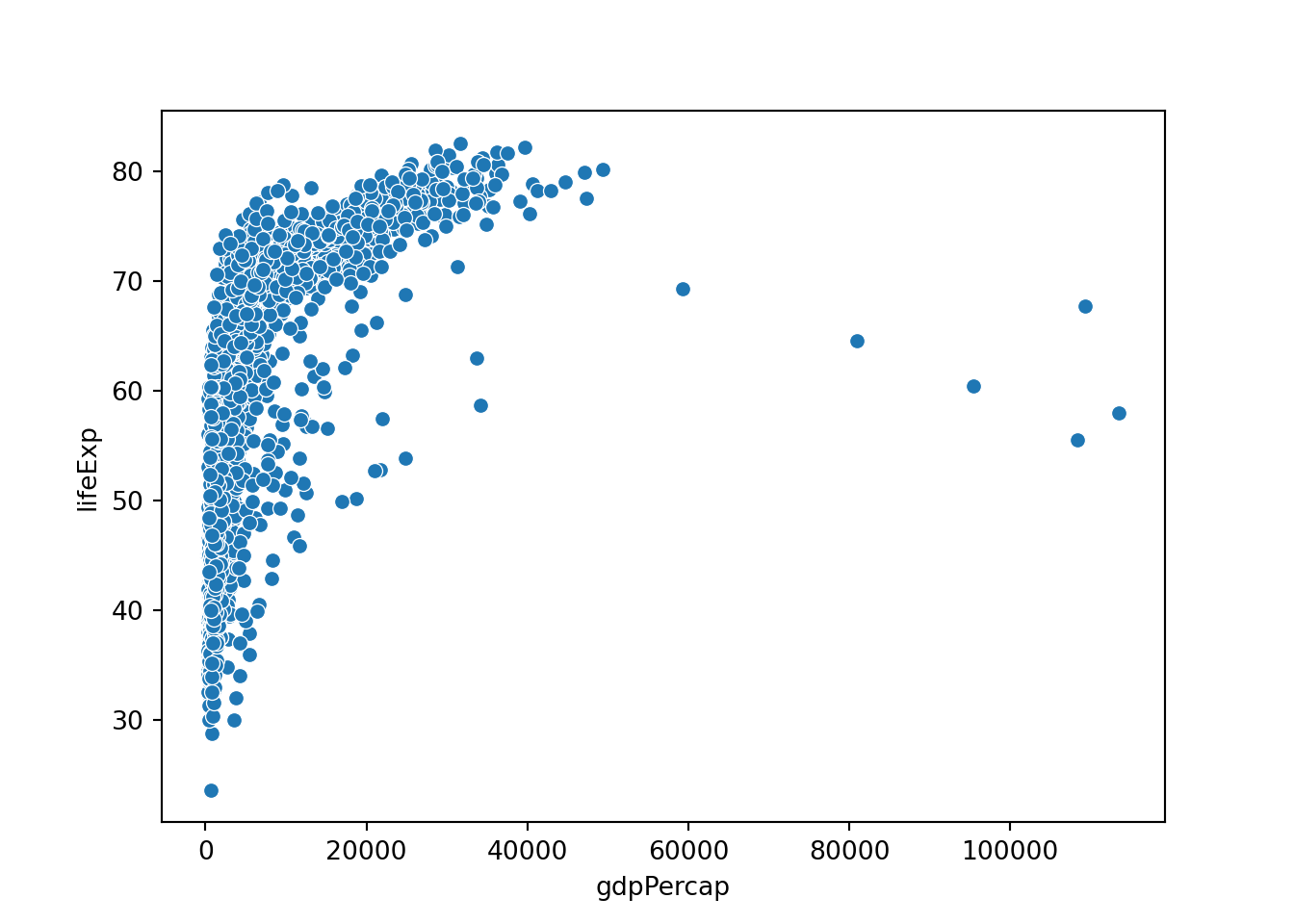
matplotlibのsctter()やseabornのscatterplot()を使います。- 同じように、適当な関数を使って、x軸とy軸を指定します。
一人あたりGDPと平均寿命の関係が直線的ではないことが分かります。
7.1.1 周辺密度付き散布図
散布図と各変数の分布(周辺密度 [marginal density])を同時に表示することもできます。seanbornのjointplot()を使ってみます。
<seaborn.axisgrid.JointGrid object at 0x7f7cb2139590>
ggplot2の場合は、拡張パッケージであるggExtraを使います。
R (ggplot2)
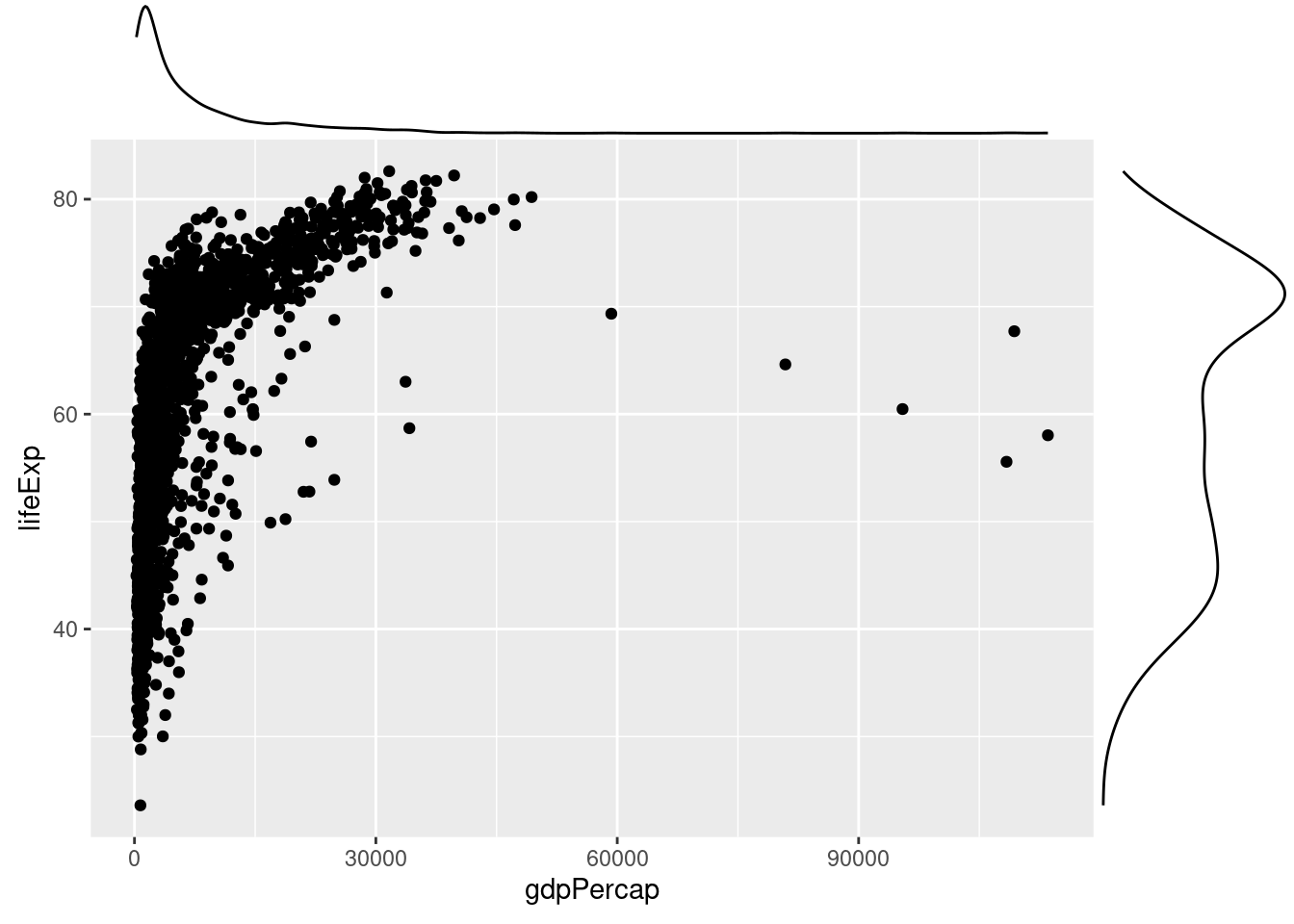
- 一度、画像をオブジェクトとして保存して、
ggMarginal()に入れます。
7.1.2 グループごとの散布図
分布のときと同様に、散布図でもグループごとに色分けすることができます。以下に見るグラフも同様です。

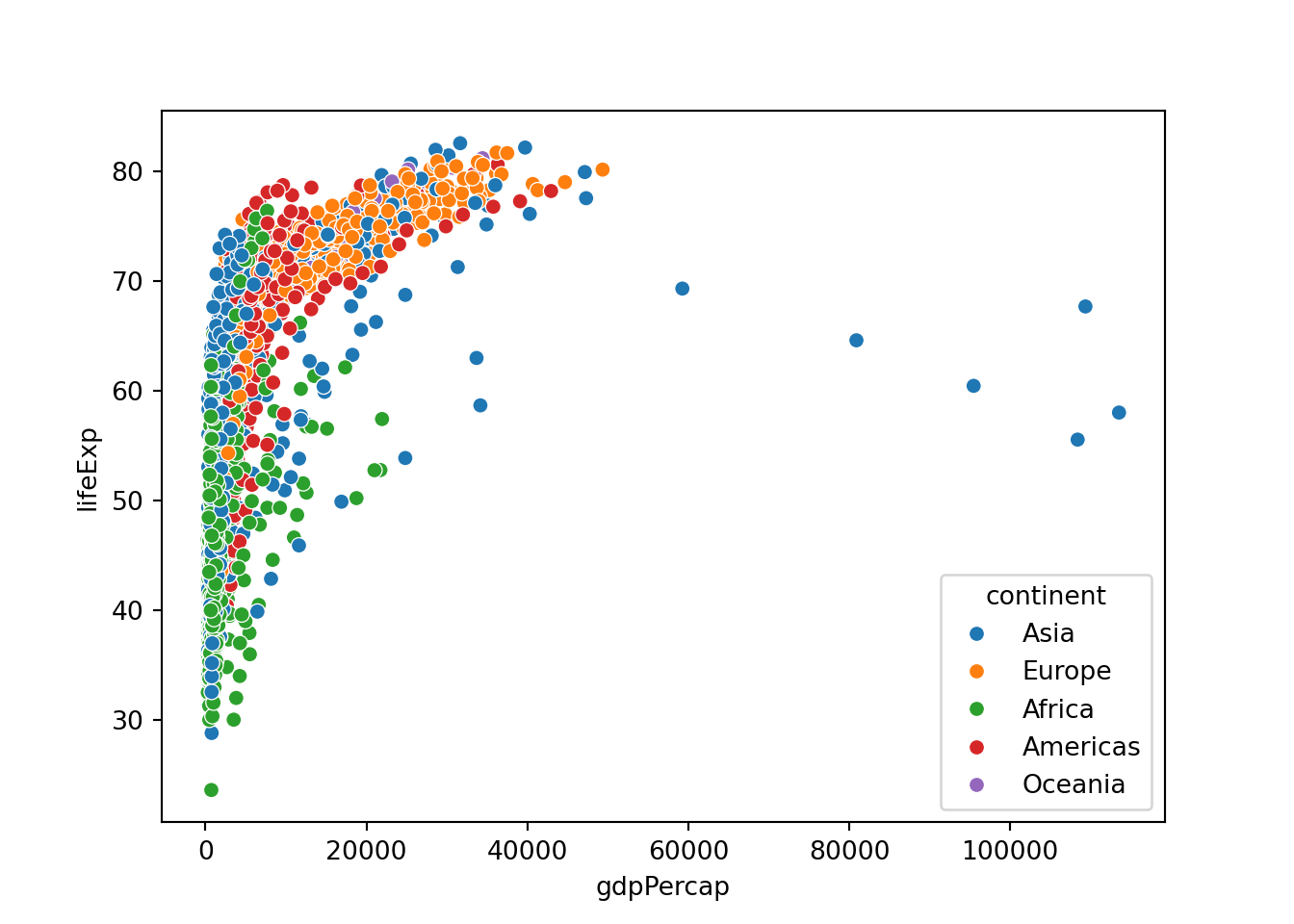
7.2 同時分布
カーネル密度プロットを二次元に拡張したグラフを作成することもできます。
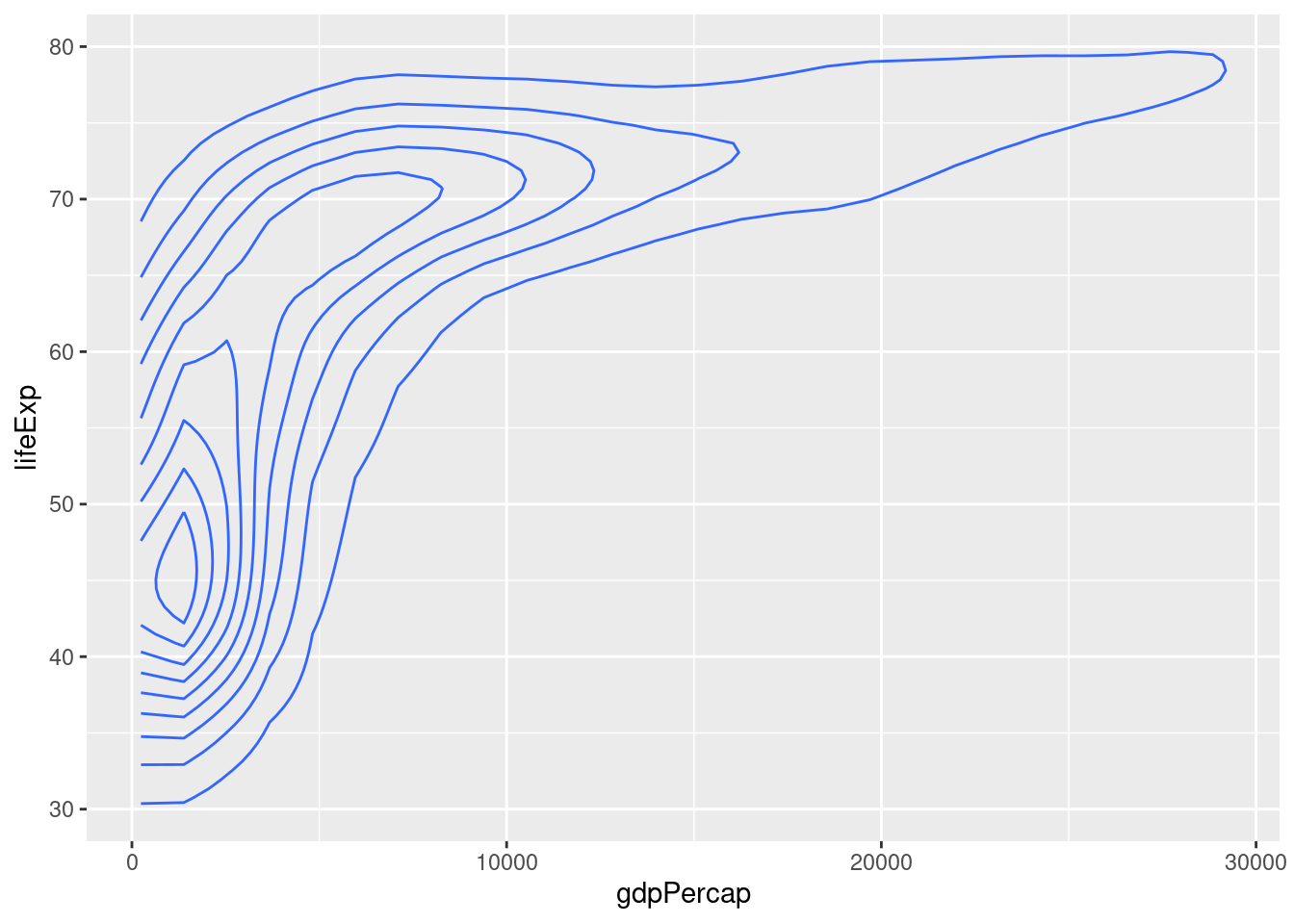
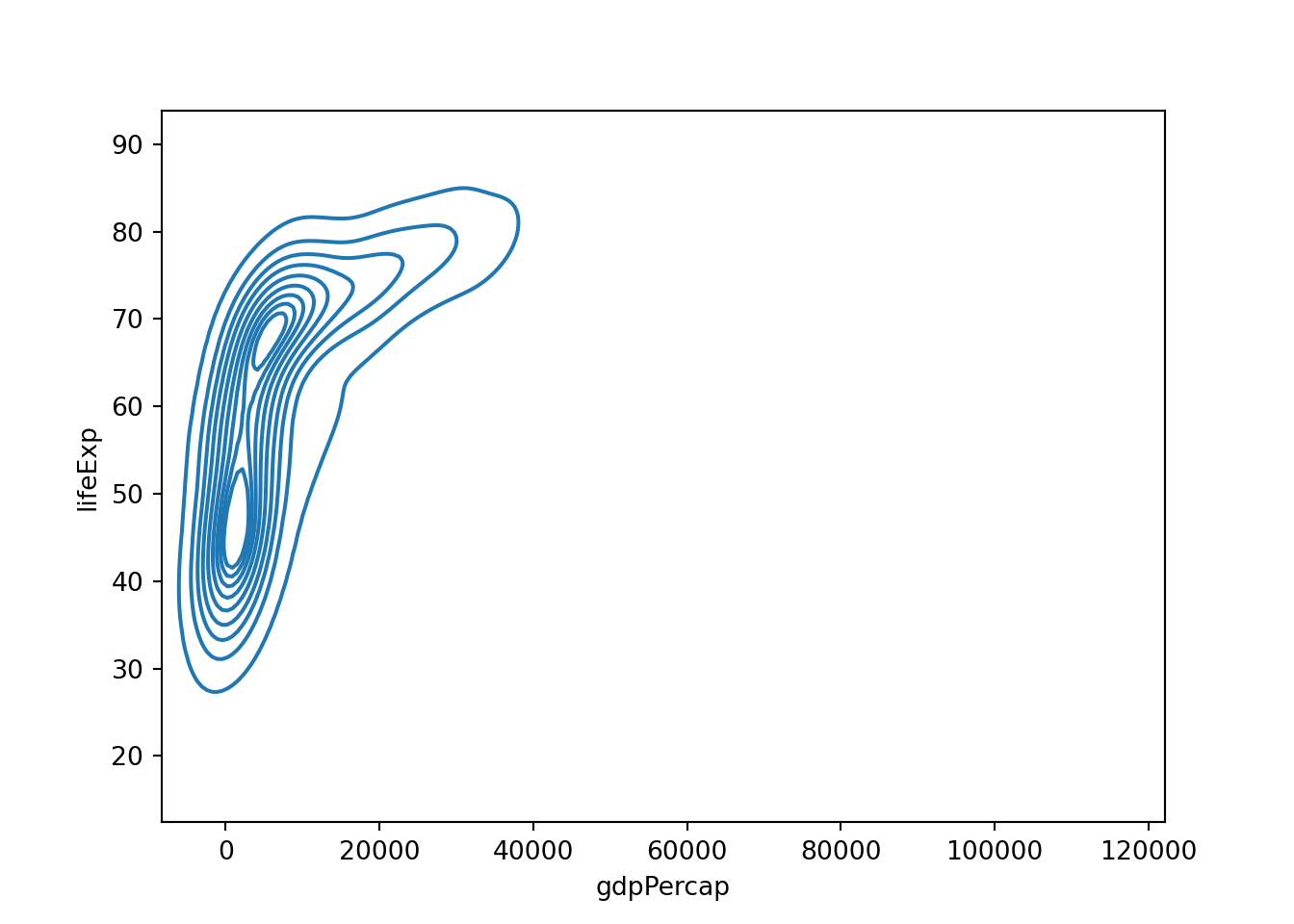
seabornだとなんかうまくいかないです。
7.3 ジッター
連続変数と離散変数の関係を見るとき、散布図を作成するとよく分からないグラフができます。
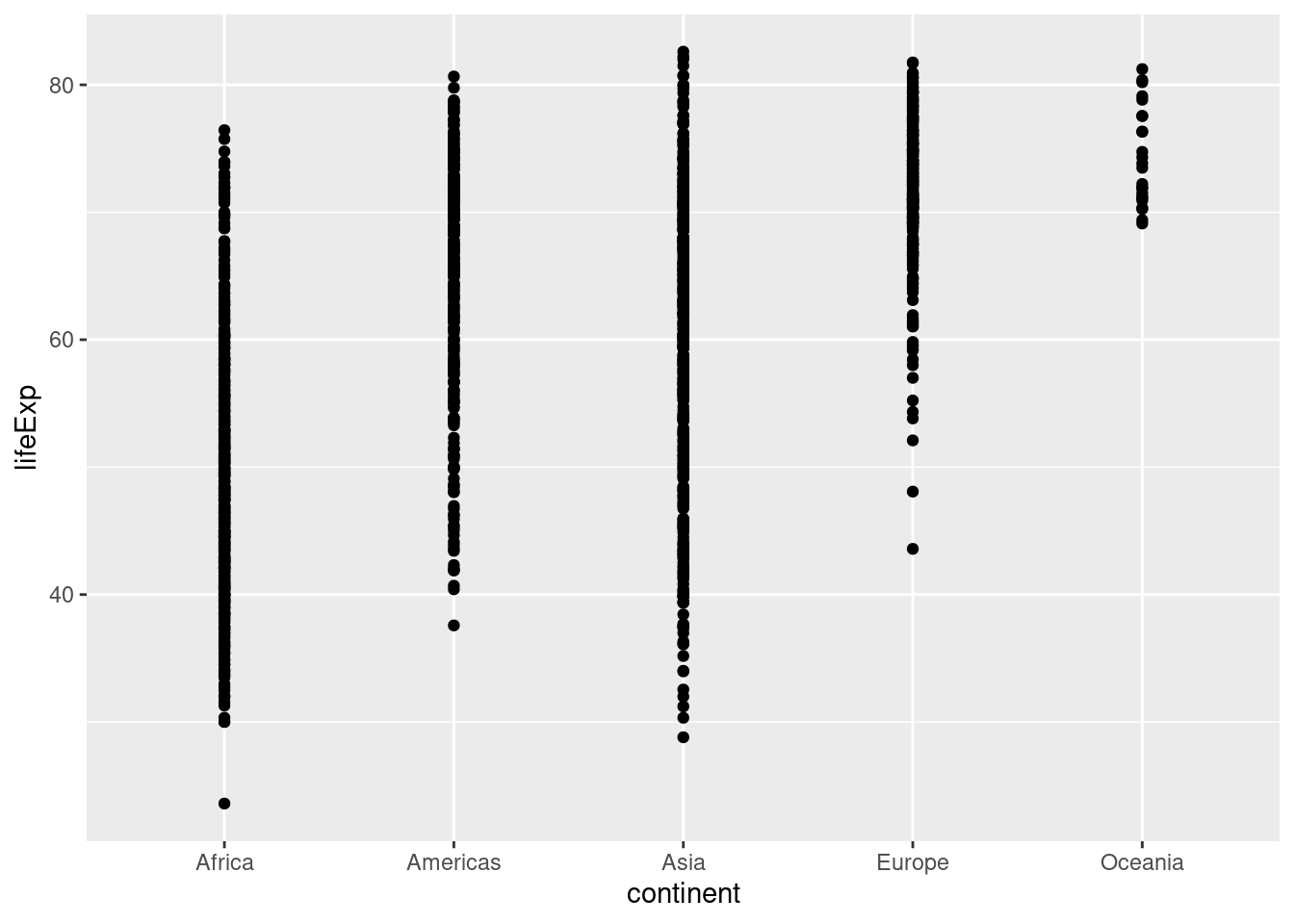
- この例では、同じ大陸にある国の平均寿命は同じ直線上に描かれるので、どのような値が多いのかは分かりにくいです。
このような場合、ジッター(ゆらぎ)を与えることで見えやすくなります。


geom_jitter()やstripplot()を使います。
7.4 複数の変数の分布と散布図
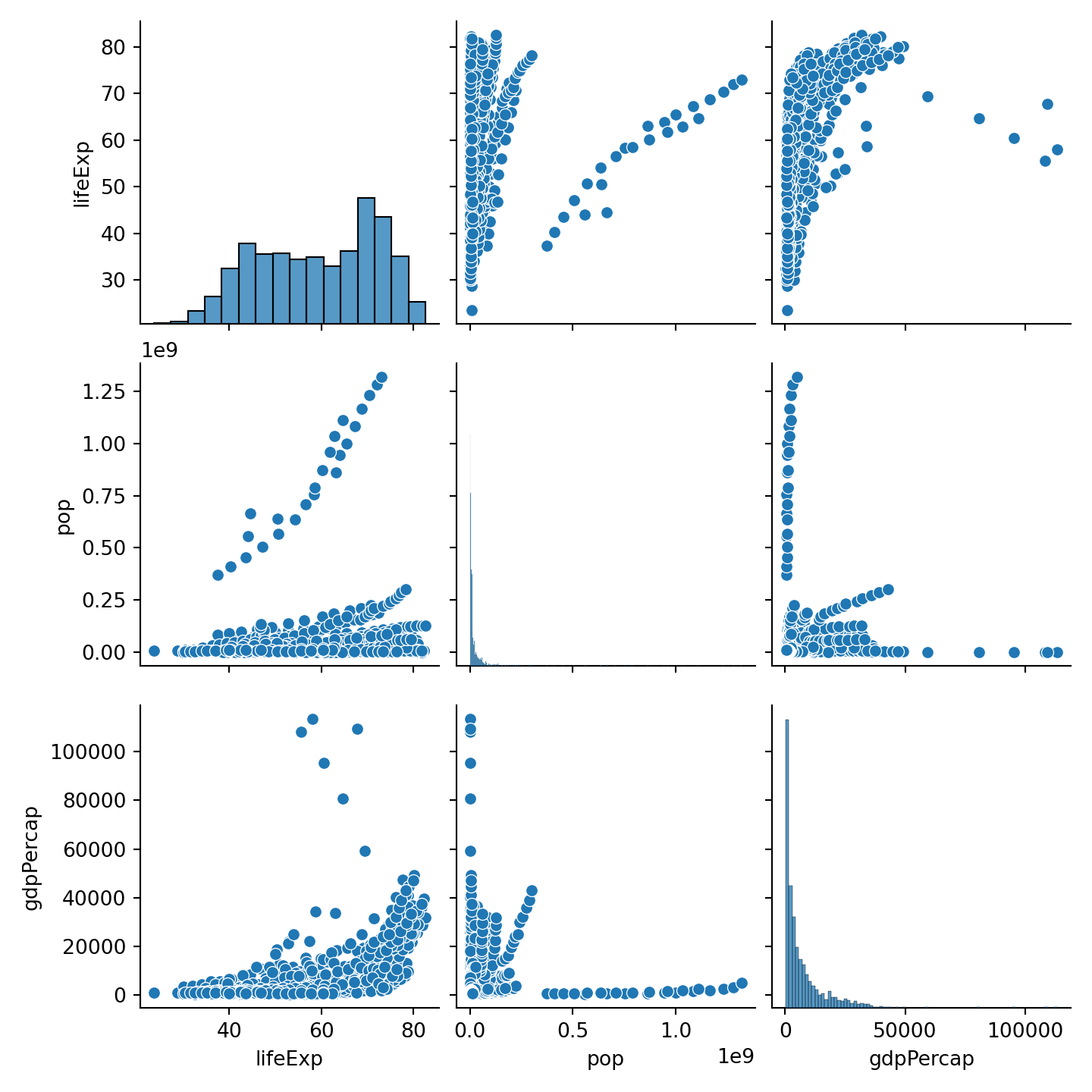
ここまで一変数の分布や二変数間の相関を可視化してきました。論文にする際には重要な変数のグラフを作成すればよいですが、データ分析を始める段階でひとまずデータの特徴を把握したい場合には、いちいちそれぞれのグラフを作るのは面倒です。
ここではデータに含まれる変数の分布や相関をひと目で可視化したいと思います。seabornのpairplot()を使います。
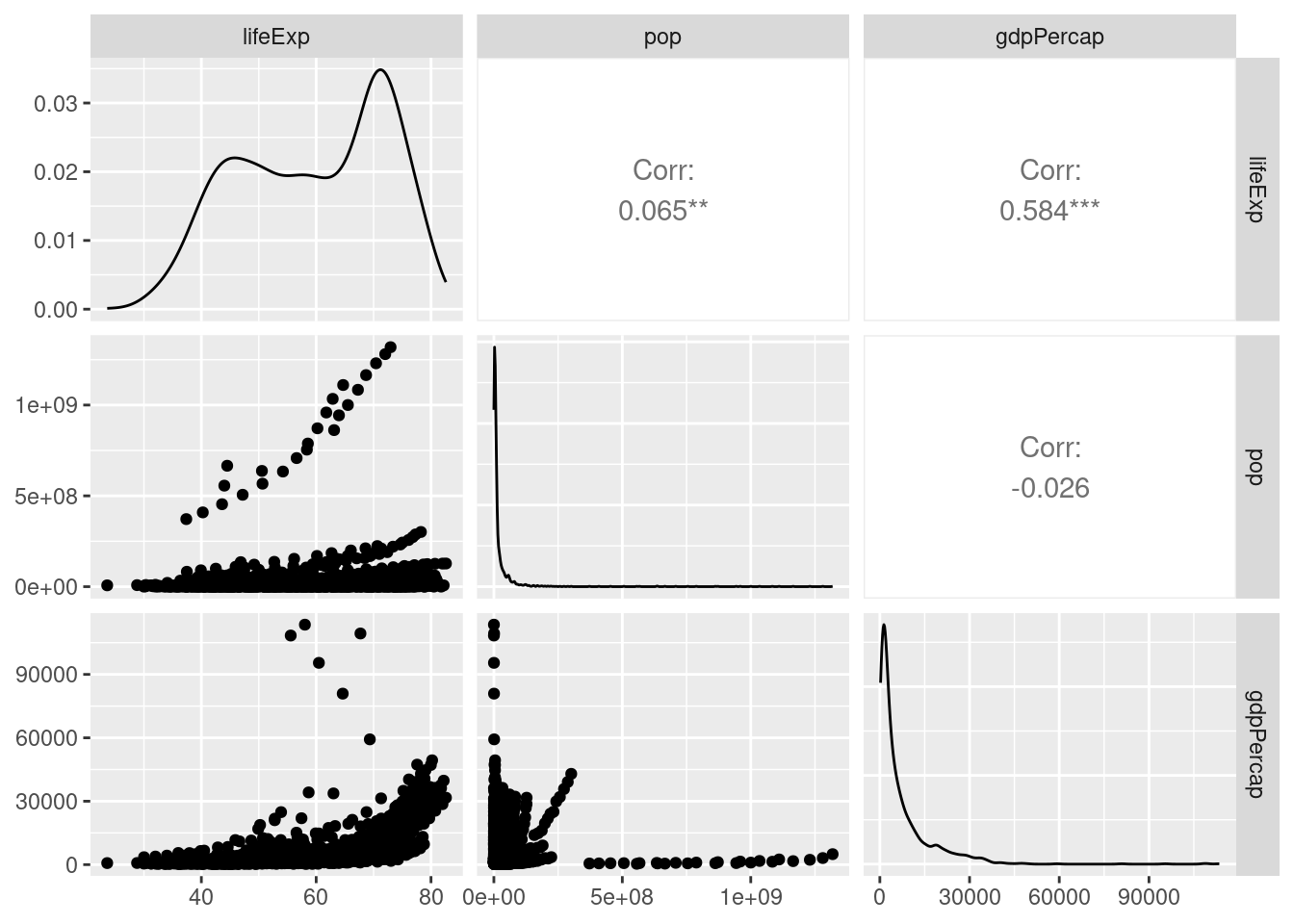
ggplot2ではGGallyというパッケージのggpairs()を使います。
7.5 棒グラフ
あるいはグループごとに平均値(や中央値)を計算し、その棒グラフを描くということも、よくやられます。
R (ggplot2)

Python (matplotlib)
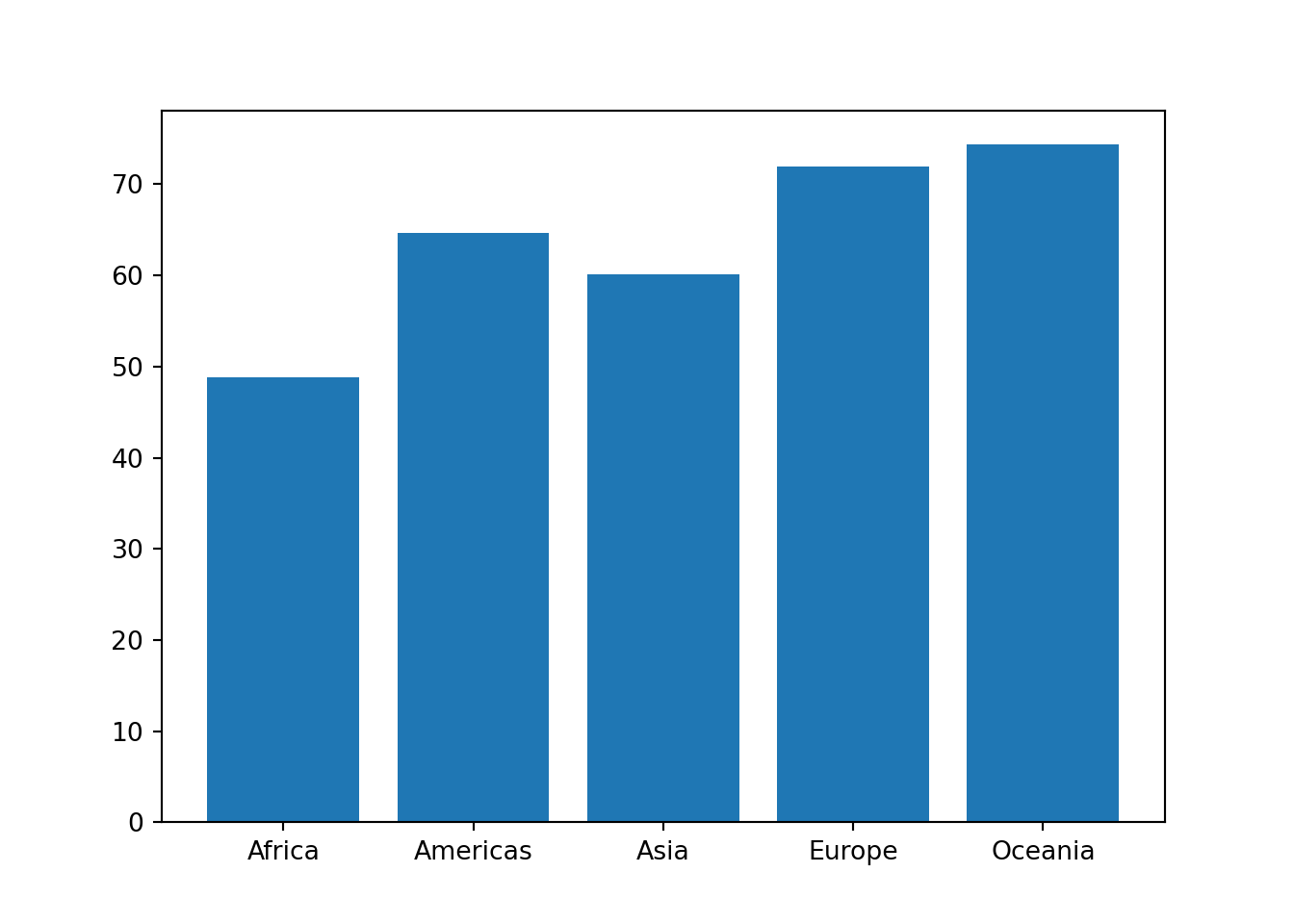
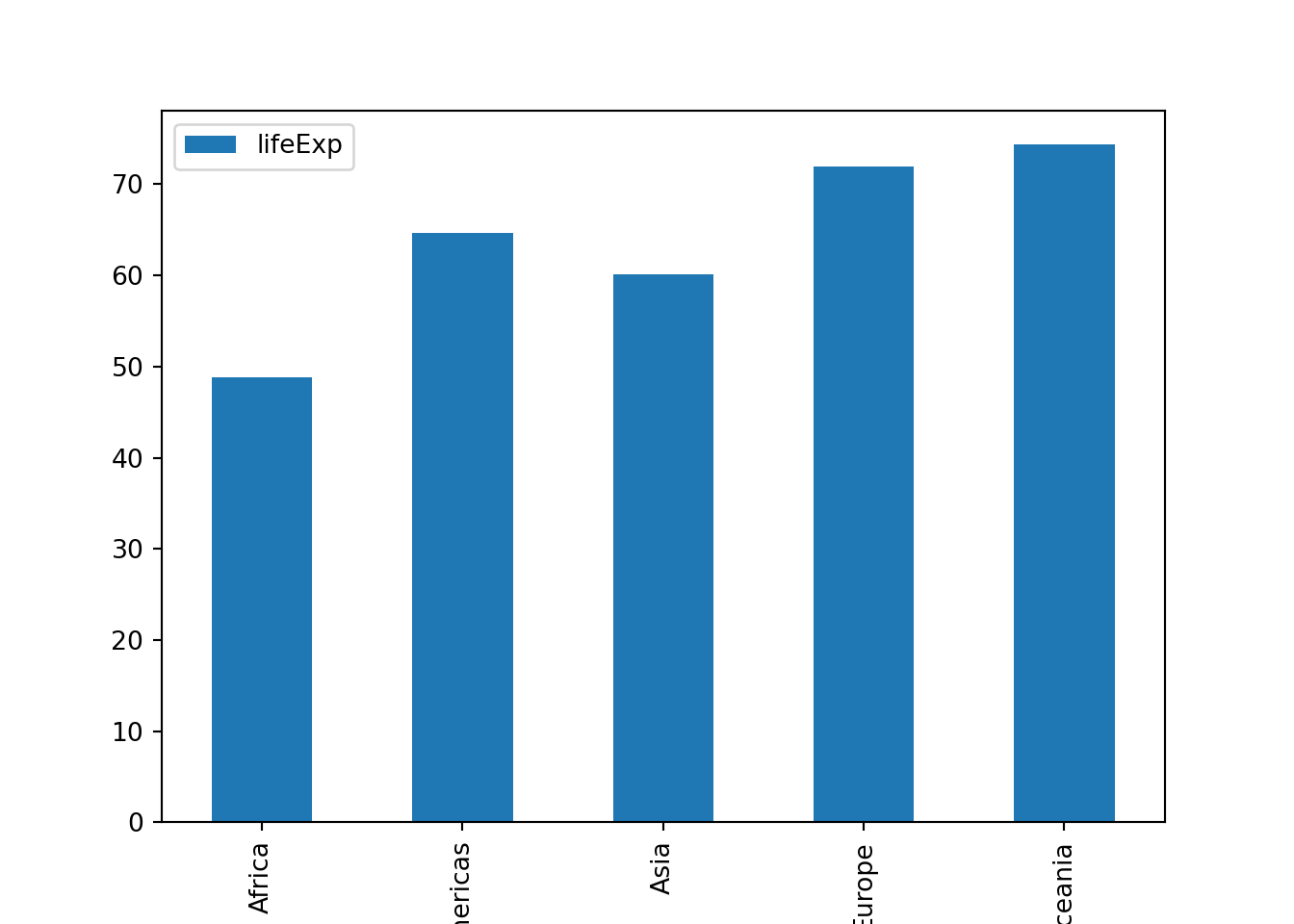
- まずはグループごとの平均寿命の平均値を求めたデータフレームを作成し、それに基づいてグラフを描きます。
seabornの場合はbarplotが自動で集計してくれます。
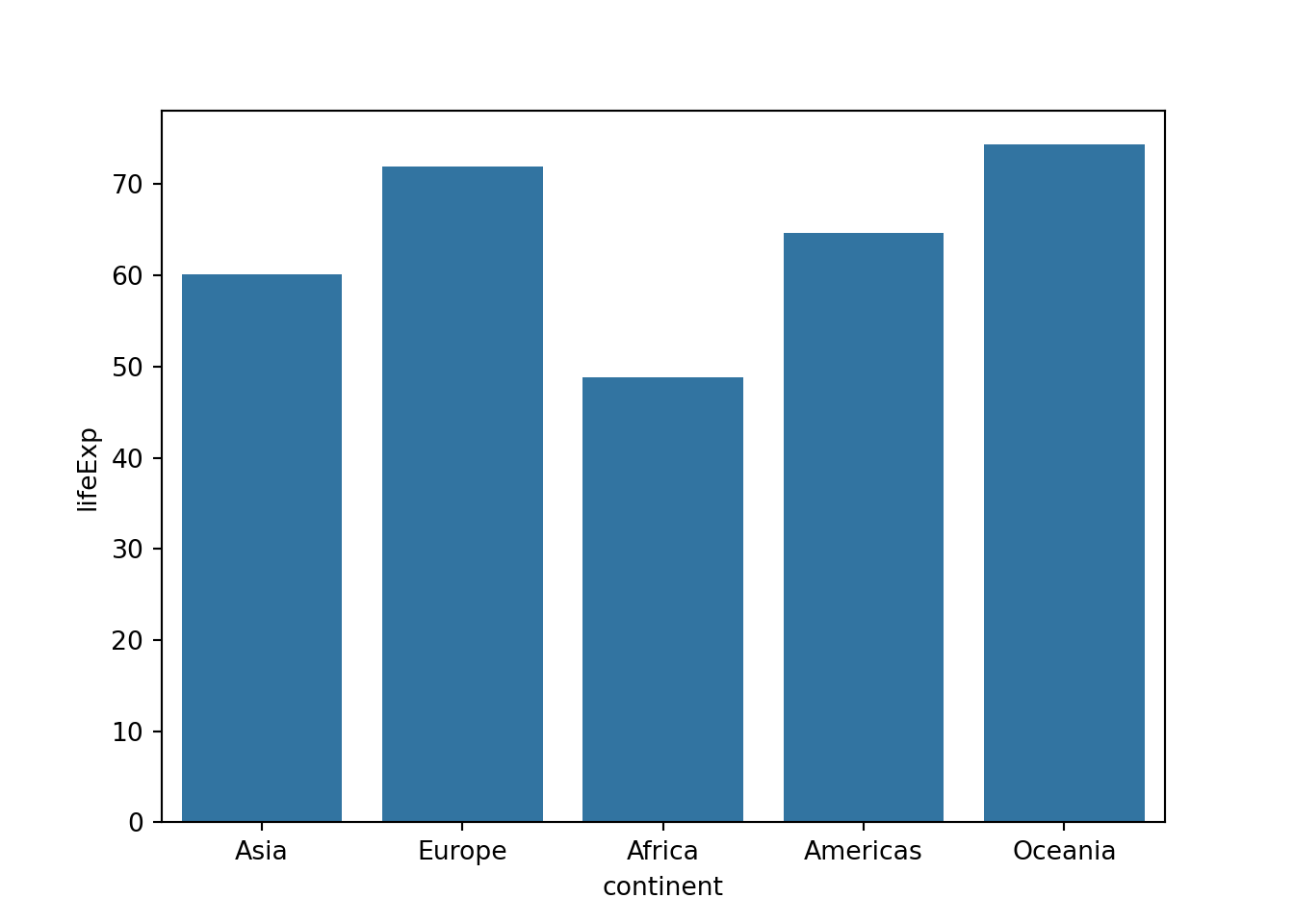
- エラーバー(後述)は表示しないように設定しておきます。
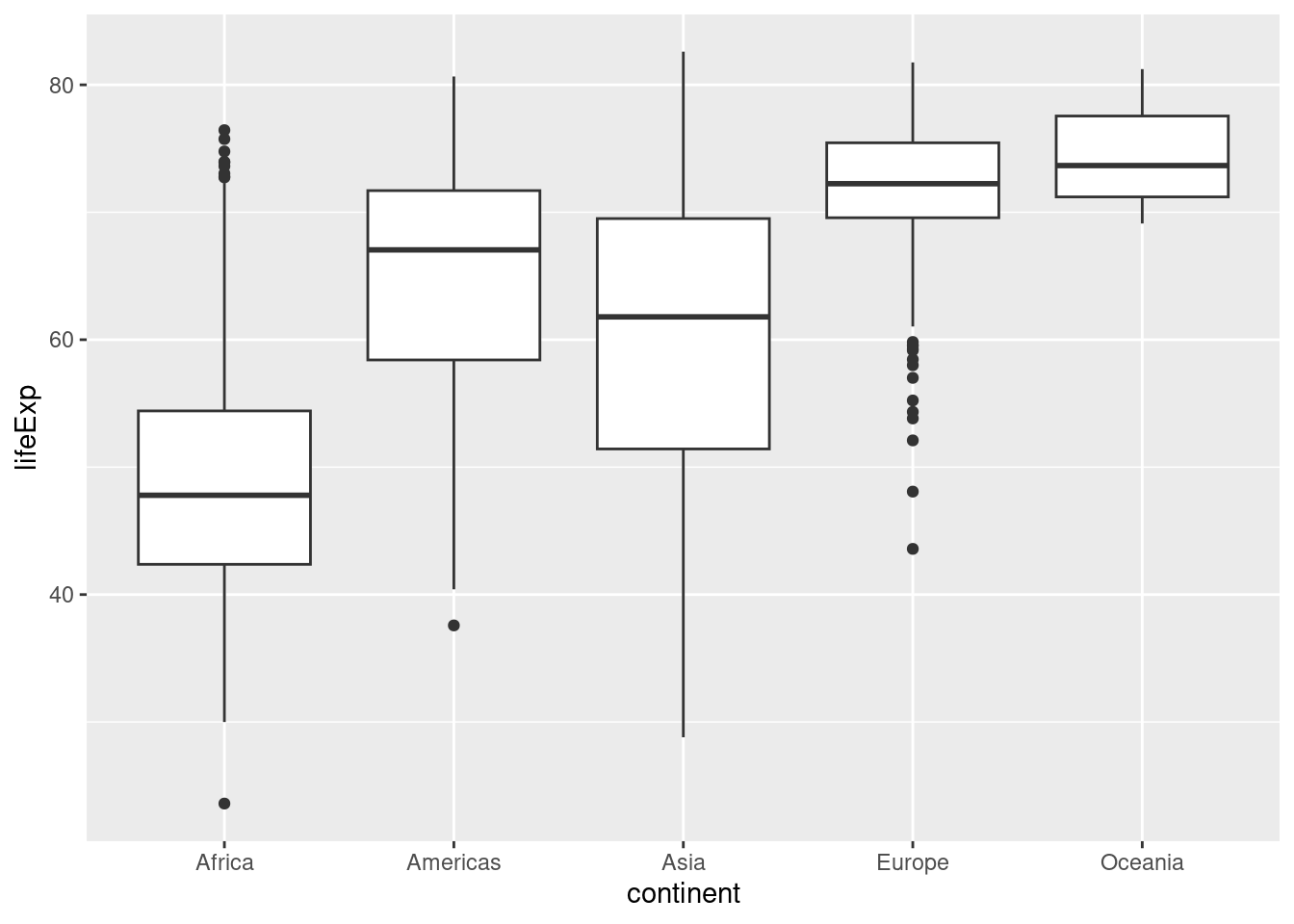
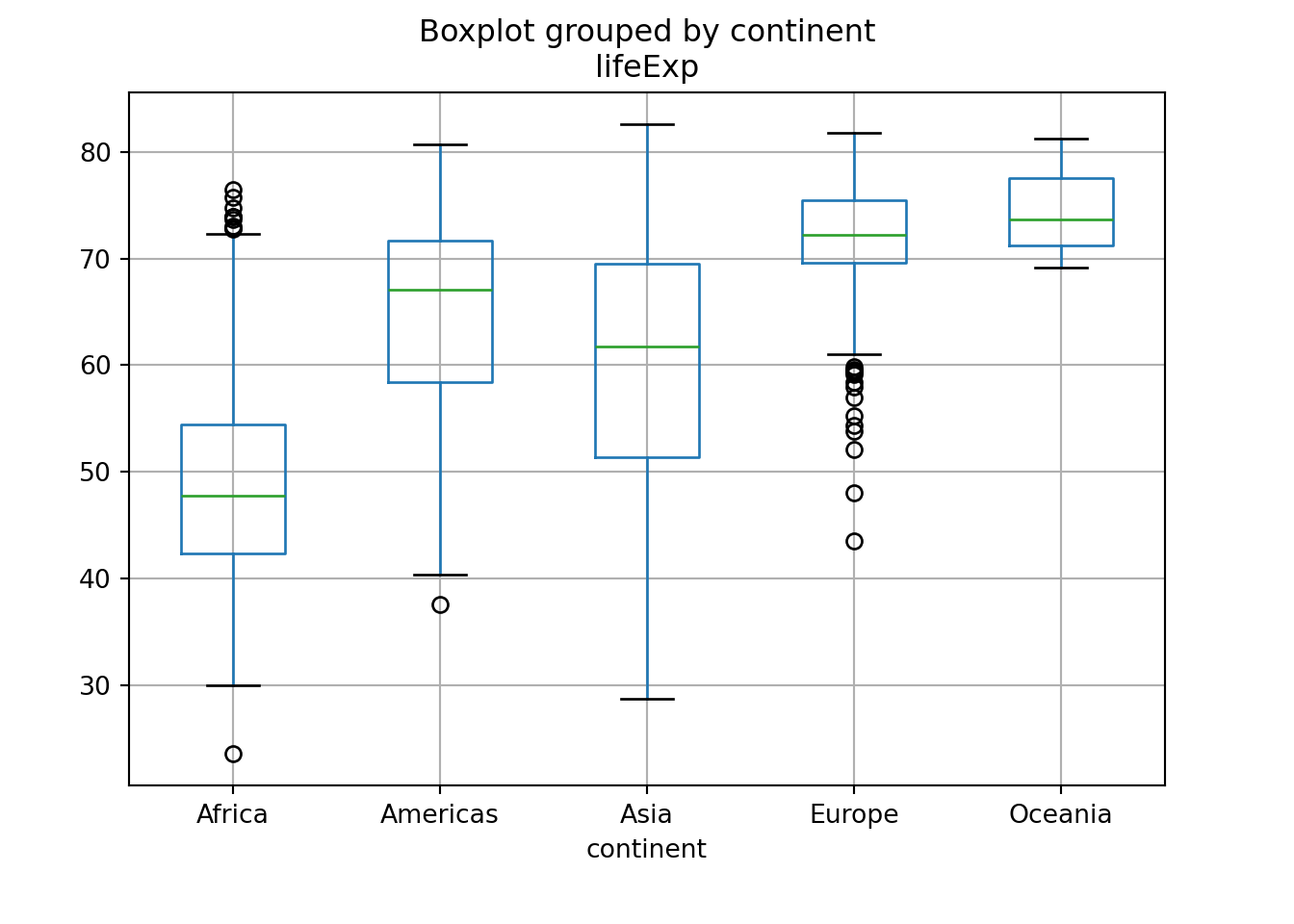
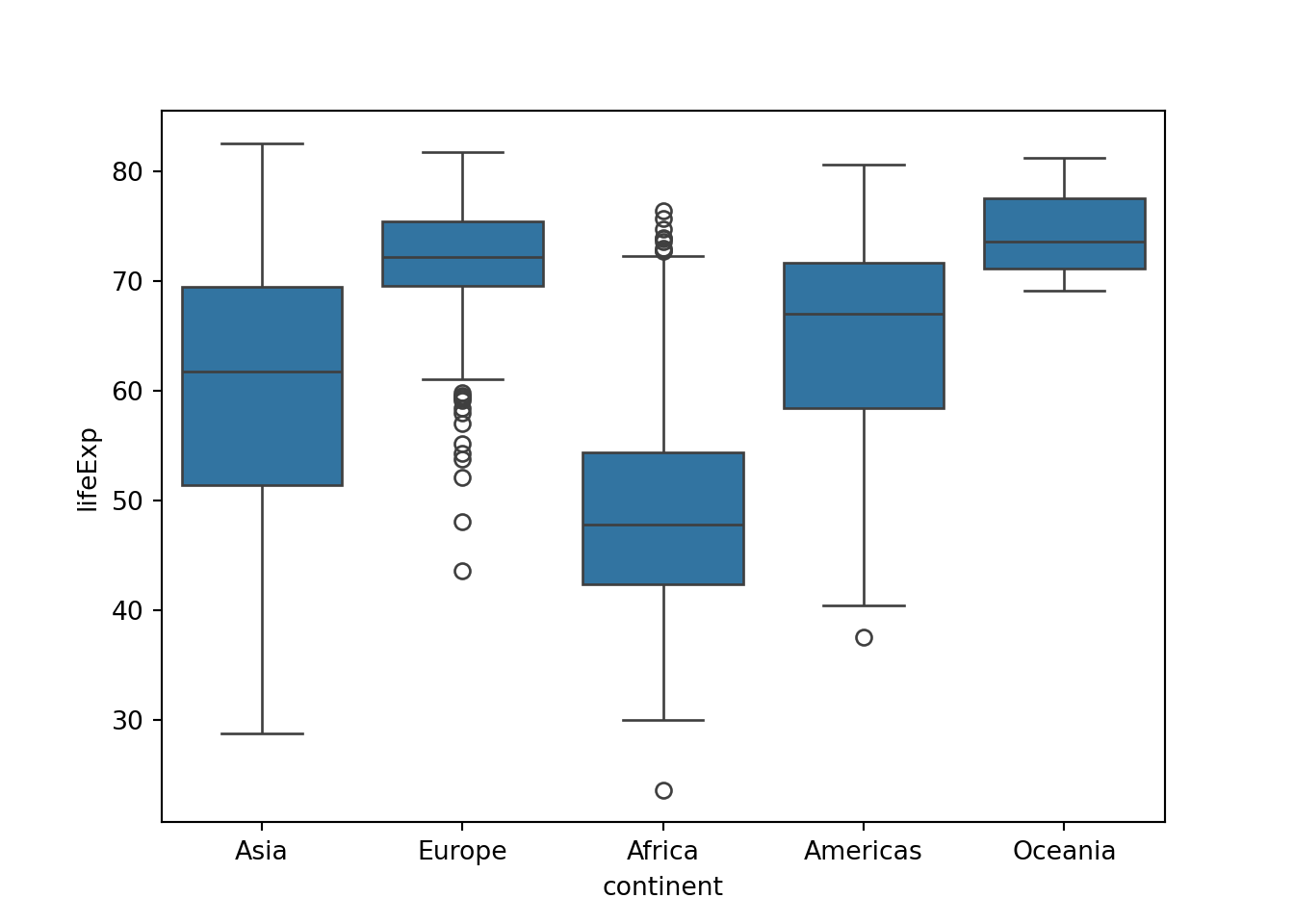
7.6 箱ひげ図
平均値の棒グラフはよく使われますが、平均値しか分からないという欠点があります。そこで、箱ひげ図 (boxplot) を使うことで平均値以外の情報も可視化できます。
lifeExp Axes(0.125,0.11;0.775x0.77)
dtype: object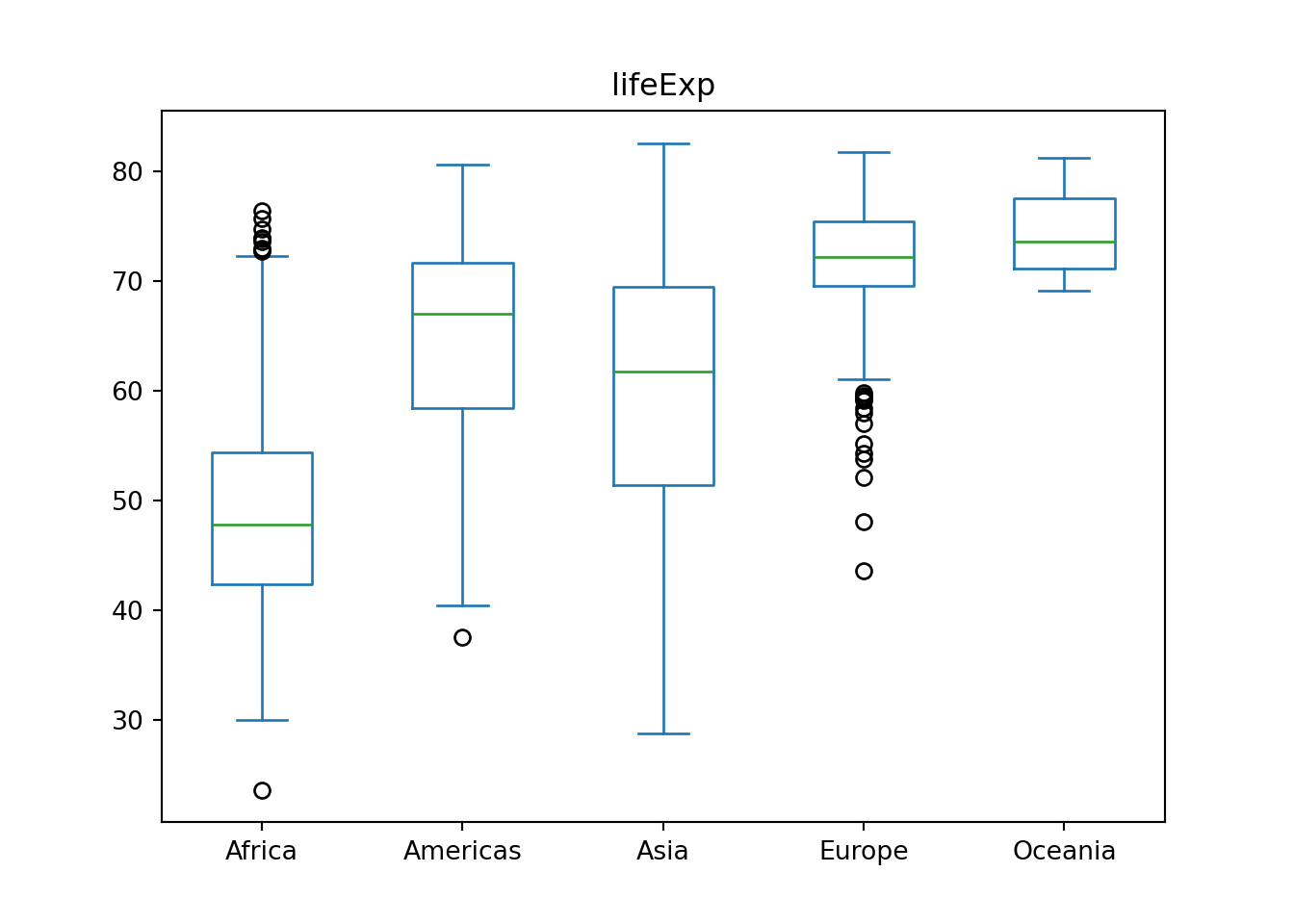
- 箱ひげ図の定義はパッケージ等によって異なるので、確認してください。例えば、wikipediaによると次のような定義となっています。

geom_boxplot()やboxplot()を使います。
例えば、ヨーロッパとオセアニアは平均値は近いですが、散らばり具合は異なることが分かります。
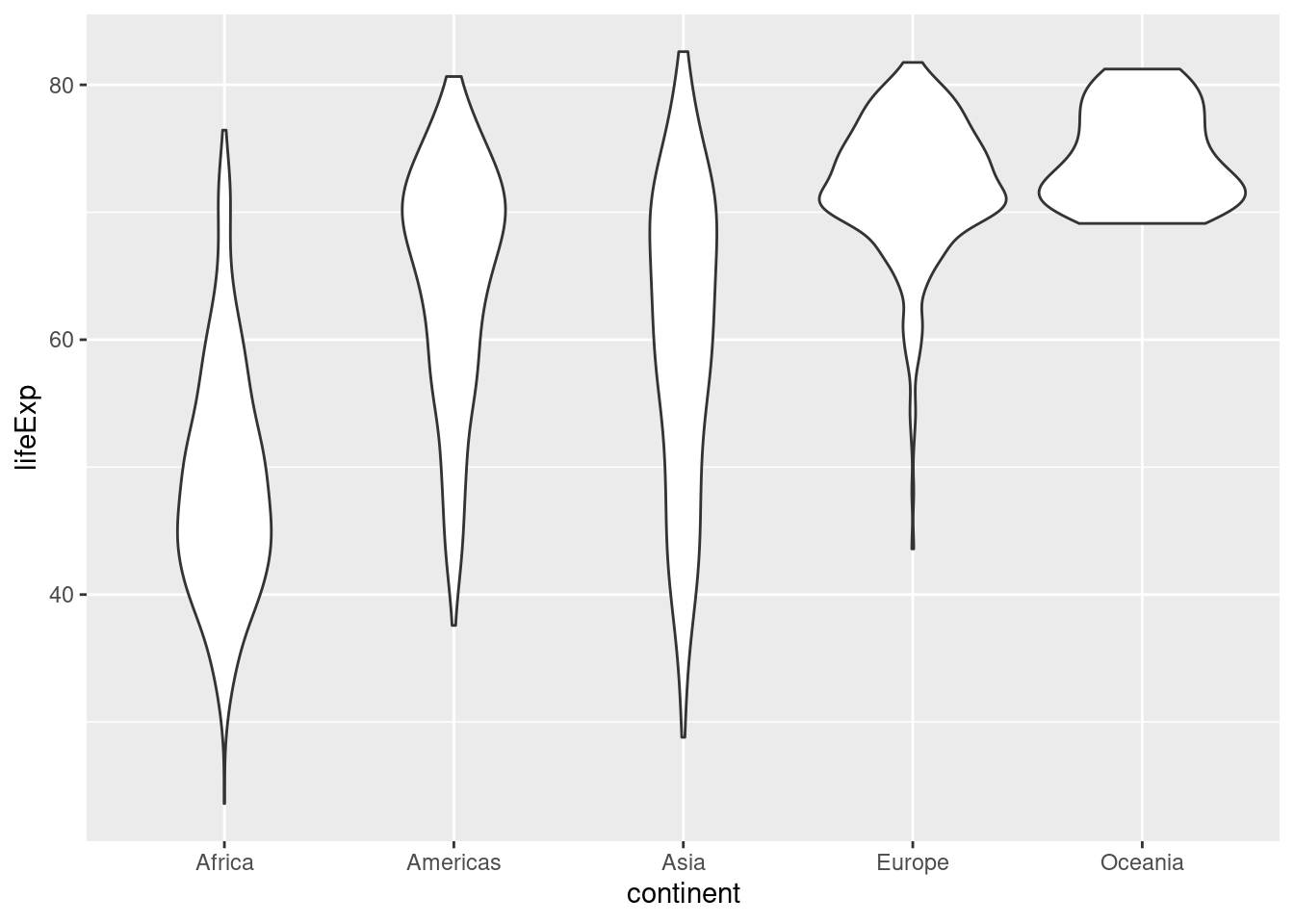
7.7 バイオリンプロット
グループごとにカーネル密度プロットを描くグラフをバイオリンプロットと呼びます。

7.8 ヒートマップ
離散変数同士の関係を見る場合はヒートマップを使います。gapminderには離散変数は大陸しか含まれていないので、無駄ではありますが、平均寿命を離散変数にしたいと思います。具体的には、平均寿命を四捨五入して10年ごとの変数を作成します(例えば58歳なら60歳)。
7.8.1 変数の追加
データフレームに変数を追加する場合は、新しい変数名を使って列を指定して、変数の内容を代入します。
# A tibble: 6 × 7
country continent year lifeExp pop gdpPercap lifeExp10
<fct> <fct> <int> <dbl> <int> <dbl> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779. 30
2 Afghanistan Asia 1957 30.3 9240934 821. 30
3 Afghanistan Asia 1962 32.0 10267083 853. 30
4 Afghanistan Asia 1967 34.0 11537966 836. 30
5 Afghanistan Asia 1972 36.1 13079460 740. 40
6 Afghanistan Asia 1977 38.4 14880372 786. 40 country continent year lifeExp pop gdpPercap lifeExp10
0 Afghanistan Asia 1952 28.801 8425333 779.445314 30.0
1 Afghanistan Asia 1957 30.332 9240934 820.853030 30.0
2 Afghanistan Asia 1962 31.997 10267083 853.100710 30.0
3 Afghanistan Asia 1967 34.020 11537966 836.197138 30.0
4 Afghanistan Asia 1972 36.088 13079460 739.981106 40.0round()という関数・メソッドで四捨五入をします。digits/decimalsでは小数点第何位で四捨五入をするのかを決めています。例えば、digits/decimals=1であれば、結果が小数点第1位になるように四捨五入をします。すなわち、小数点第2位に基づいて四捨五入をします。したがって、digits/decimals=-1であれば小数点第-1位(そんなものはありませんが)、すなわち1の位で四捨五入をします。
7.8.2 ヒートマップの作図
それでは、ヒートマップを作図します。そのために、大陸ごとに10歳ごとの平均寿命が同じ国の数を計算します。
R (ggplot2)
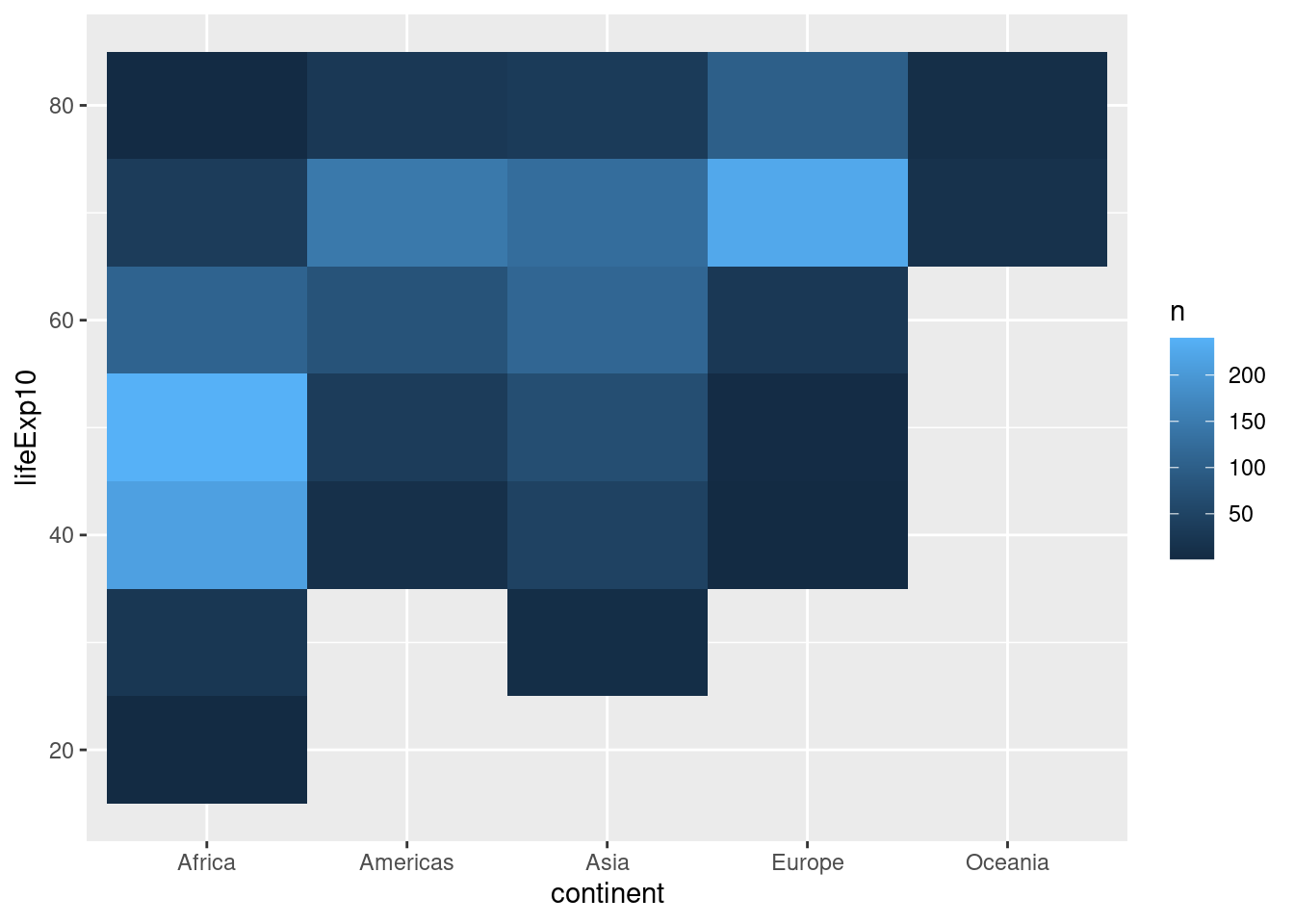
count()によって変数の値(ここでは大陸及び四捨五入済み平均寿命)ごとに観察数を計算します。geom_tile()でヒートマップを作成しますが、fillによってどの変数によって色を塗るか決めます。ここでは観察数であるn(count()によって作成された変数)を指定します。
Pythonでヒートマップを作図するには、ひと手間かかります。いずれ改めて触れたいと思います。