13 データの選択
データフレームに含まれるデータのうちで実際に分析に使うのは一部ということはよくあります。その場合は不要なデータを削除していたほうが見やすいですし、PCへの負担も少なくなると思います。
なお、以下ではRの標準関数を使う場合、tidyverseのdplyrを使う場合、Pythonのpadansを使う場合、polarsを使う場合を紹介します。
13.1 変数の選択
まずは、特定の変数だけを使う場合を考えます。例えば、以前読み込んだPolityのデータから特定の変数だけを取り出します。具体的には、ccodeとcountry、year、polity2だけを取り出します。
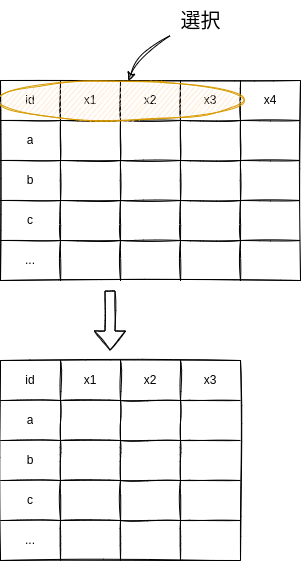
13.1.1 変数名による選択
R (base)
# A tibble: 6 × 4
ccode country year polity2
<dbl> <chr> <dbl> <dbl>
1 700 Afghanistan 1800 -6
2 700 Afghanistan 1801 -6
3 700 Afghanistan 1802 -6
4 700 Afghanistan 1803 -6
5 700 Afghanistan 1804 -6
6 700 Afghanistan 1805 -6R (tidyverse)
# A tibble: 6 × 4
ccode country year polity2
<dbl> <chr> <dbl> <dbl>
1 700 Afghanistan 1800 -6
2 700 Afghanistan 1801 -6
3 700 Afghanistan 1802 -6
4 700 Afghanistan 1803 -6
5 700 Afghanistan 1804 -6
6 700 Afghanistan 1805 -6Python (pandas)
ccode country year polity2
0 700 Afghanistan 1800 -6.0
1 700 Afghanistan 1801 -6.0
2 700 Afghanistan 1802 -6.0
3 700 Afghanistan 1803 -6.0
4 700 Afghanistan 1804 -6.0Python (polars)
| ccode | country | year | polity2 |
|---|---|---|---|
| i64 | str | i64 | i64 |
| 700 | "Afghanistan" | 1800 | -6 |
| 700 | "Afghanistan" | 1801 | -6 |
| 700 | "Afghanistan" | 1802 | -6 |
| 700 | "Afghanistan" | 1803 | -6 |
| 700 | "Afghanistan" | 1804 | -6 |
いずれも期待通りの結果が出ています。ところで、上の4つのコードを見比べていると共通性があることが分かります。
- Rの標準関数およびPythonの
pandasでは,の右側で変数名を入力することで変数を選択しています。pandasの場合はloc属性を使っていること、,の左に「全て」を意味する:が入っている点に注意。
- 一方、Rの
tidyverseとPythonのpolarsではselect()を使って変数名を選択しています。
13.1.2 番号による選択
あまり使う機会はありませんが、変数の番号を指定して選択することもできます。それぞれ、3, 5, 6, 12番目の変数です。
R (base)
# A tibble: 6 × 4
ccode country year polity2
<dbl> <chr> <dbl> <dbl>
1 700 Afghanistan 1800 -6
2 700 Afghanistan 1801 -6
3 700 Afghanistan 1802 -6
4 700 Afghanistan 1803 -6
5 700 Afghanistan 1804 -6
6 700 Afghanistan 1805 -6Python (pandas)
ccode country year polity2
0 700 Afghanistan 1800 -6.0
1 700 Afghanistan 1801 -6.0
2 700 Afghanistan 1802 -6.0
3 700 Afghanistan 1803 -6.0
4 700 Afghanistan 1804 -6.0locの代わりにilocを使います。
Rは1から始まるので番号をそのまま入力すればいいですが、Pythonは0から始まるので1引いた数を入力します。
- 直観的にはRの方が自然ですが、プログラミングでは0から始まるのが標準的です。
13.2 変数名の変更
変数の選択ではないですが、ついでに変数名を変更する方法を説明します。例えば、世銀のデータではCountry Nameのように空白が変数名に入っていましたが、変数名に空白が入ることは(特にtidyverseを使う上で)不都合があります。変数名を変更したいと思います。
R (tidyverse)
# A tibble: 6 × 69
country_name coutnry_code indicator_name indicator_code `1960` `1961` `1962`
<chr> <chr> <chr> <chr> <dbl> <dbl> <dbl>
1 Aruba ABW Population, f… SP.POP.TOTL.F… 2.78e4 2.84e4 2.88e4
2 Africa Easter… AFE Population, f… SP.POP.TOTL.F… 6.59e7 6.76e7 6.95e7
3 Afghanistan AFG Population, f… SP.POP.TOTL.F… 4.15e6 4.23e6 4.33e6
4 Africa Wester… AFW Population, f… SP.POP.TOTL.F… 4.88e7 4.99e7 5.09e7
5 Angola AGO Population, f… SP.POP.TOTL.F… 2.67e6 2.70e6 2.74e6
6 Albania ALB Population, f… SP.POP.TOTL.F… 7.85e5 8.09e5 8.34e5
# ℹ 62 more variables: `1963` <dbl>, `1964` <dbl>, `1965` <dbl>, `1966` <dbl>,
# `1967` <dbl>, `1968` <dbl>, `1969` <dbl>, `1970` <dbl>, `1971` <dbl>,
# `1972` <dbl>, `1973` <dbl>, `1974` <dbl>, `1975` <dbl>, `1976` <dbl>,
# `1977` <dbl>, `1978` <dbl>, `1979` <dbl>, `1980` <dbl>, `1981` <dbl>,
# `1982` <dbl>, `1983` <dbl>, `1984` <dbl>, `1985` <dbl>, `1986` <dbl>,
# `1987` <dbl>, `1988` <dbl>, `1989` <dbl>, `1990` <dbl>, `1991` <dbl>,
# `1992` <dbl>, `1993` <dbl>, `1994` <dbl>, `1995` <dbl>, `1996` <dbl>, …Python (pandas)
country_name coutnry_code ... 2023 Unnamed: 68
0 Aruba ABW ... NaN NaN
1 Africa Eastern and Southern AFE ... NaN NaN
2 Afghanistan AFG ... NaN NaN
3 Africa Western and Central AFW ... NaN NaN
4 Angola AGO ... NaN NaN
[5 rows x 69 columns]Python (polars)
| country_name | coutnry_code | indicator_name | indicator_code | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | 1966 | 1967 | 1968 | 1969 | 1970 | 1971 | 1972 | 1973 | 1974 | 1975 | 1976 | 1977 | 1978 | 1979 | 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| str | str | str | str | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | str | str |
| "Aruba" | "ABW" | "Population, fe… | "SP.POP.TOTL.FE… | 27773 | 28380 | 28820 | 29218 | 29570 | 29875 | 30135 | 30253 | 30232 | 30166 | 30063 | 29927 | 29953 | 30229 | 30595 | 30972 | 31245 | 31416 | 31584 | 31749 | 31909 | 32121 | 32389 | 32659 | 32886 | 33008 | 33007 | 32904 | 32788 | 32892 | 33480 | 34657 | 35941 | 37137 | 38437 | 39724 | 41014 | 42336 | 43688 | 45050 | 46269 | 47178 | 47831 | 48374 | 48877 | 49414 | 50016 | 50636 | 51272 | 51919 | 52484 | 52980 | 53480 | 53953 | 54403 | 54828 | 55224 | 55591 | 55935 | 56254 | 56373 | 56330 | 56272 | "" | null |
| "Africa Eastern… | "AFE" | "Population, fe… | "SP.POP.TOTL.FE… | 65853220 | 67606287 | 69457112 | 71375643 | 73386167 | 75478396 | 77610073 | 79810945 | 82111287 | 84493601 | 86968714 | 89504801 | 92051419 | 94694181 | 97478670 | 100339888 | 103289004 | 106237590 | 109415983 | 112834021 | 116060576 | 119525759 | 123410049 | 127333314 | 131344567 | 135563206 | 139816011 | 144066893 | 148288335 | 152522362 | 156942214 | 161298074 | 165609524 | 170167926 | 174762745 | 179486372 | 184468529 | 189280003 | 194009070 | 198959676 | 204048614 | 209257664 | 214635664 | 220167814 | 225898442 | 231830259 | 237997868 | 244435307 | 251105628 | 257956460 | 265000967 | 272174714 | 279546577 | 287224924 | 295089133 | 303195897 | 311387401 | 319637365 | 328159112 | 336930970 | 345889868 | 354855221 | 363834524 | "" | null |
| "Afghanistan" | "AFG" | "Population, fe… | "SP.POP.TOTL.FE… | 4145945 | 4233771 | 4326881 | 4424511 | 4526691 | 4634341 | 4745981 | 4861918 | 4983086 | 5108507 | 5239568 | 5372747 | 5509781 | 5655304 | 5803603 | 5948268 | 6083166 | 6214979 | 6342838 | 6373547 | 6136856 | 5490160 | 4973968 | 4916351 | 5074600 | 5225679 | 5207273 | 5152650 | 5188060 | 5334609 | 5346409 | 5372208 | 6028939 | 7000119 | 7722096 | 8199445 | 8537421 | 8871958 | 9217591 | 9595036 | 9727541 | 9793166 | 10438055 | 11247647 | 11690825 | 12109086 | 12614497 | 12835340 | 13088192 | 13557331 | 13949295 | 14468875 | 15067373 | 15594637 | 16172321 | 16682054 | 17115346 | 17614722 | 18136922 | 18679089 | 19279930 | 19844584 | 20362329 | "" | null |
| "Africa Western… | "AFW" | "Population, fe… | "SP.POP.TOTL.FE… | 48802898 | 49850088 | 50928609 | 52044907 | 53196730 | 54389295 | 55621877 | 56890201 | 58204276 | 59560501 | 60963620 | 62404746 | 63900687 | 65482730 | 67160750 | 68943269 | 70786681 | 72718234 | 74770813 | 76909670 | 79104037 | 81359426 | 83714354 | 85996392 | 88238093 | 90605997 | 93047700 | 95556172 | 98139171 | 100824162 | 103478502 | 106184462 | 109071980 | 111968903 | 114896750 | 117979287 | 121143186 | 124399328 | 127775360 | 131211380 | 134795501 | 138546839 | 142408066 | 146370538 | 150463219 | 154696476 | 159035017 | 163481052 | 168058833 | 172782717 | 177645233 | 182657978 | 187755307 | 192900081 | 198163527 | 203513873 | 208980433 | 214578994 | 220253839 | 226004857 | 231877590 | 237813580 | 243821774 | "" | null |
| "Angola" | "AGO" | "Population, fe… | "SP.POP.TOTL.FE… | 2670229 | 2704394 | 2742689 | 2779473 | 2812590 | 2838939 | 2856740 | 2867926 | 2879001 | 2902120 | 2953347 | 3032948 | 3132441 | 3244749 | 3362438 | 3483416 | 3606782 | 3735823 | 3872130 | 4014347 | 4164145 | 4321167 | 4485276 | 4656894 | 4834820 | 5018620 | 5206761 | 5396035 | 5588733 | 5787505 | 5991207 | 6199060 | 6408303 | 6621767 | 6845622 | 7077381 | 7315200 | 7561436 | 7813123 | 8071413 | 8339311 | 8619083 | 8912191 | 9219638 | 9545020 | 9886765 | 10244381 | 10620174 | 11013001 | 11422969 | 11853530 | 12303450 | 12770743 | 13252938 | 13746371 | 14248799 | 14764575 | 15293335 | 15828040 | 16370553 | 16910989 | 17452283 | 17998220 | "" | null |
いずれもrename()を使って元の変数名と新しい変数名の対応関係を入力します。
tidyverseの場合は新変数名 = 旧変数名ですが、pandas/polarsの場合は旧変数名: 新変数名です。tidyverseのselect()の中でも変数名を変更することができます。
13.3 変数の除外
特定の変数を選択するのではなく、除外したいときがあるかもしれません。例えば、SIPRIの軍事費データのNotesは不要な気がします。
tidyverseではselect()の際に!を付けると変数を除外します。
R (readxl)
# A tibble: 6 × 76
Country ...2 `1949.0` `1950.0` `1951.0` `1952.0` `1953.0` `1954.0` `1955.0`
<chr> <lgl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 <NA> NA NA NA NA NA NA NA NA
2 Africa NA NA NA NA NA NA NA NA
3 North Af… NA NA NA NA NA NA NA NA
4 Algeria NA NA NA NA NA NA NA NA
5 Libya NA NA NA NA NA NA NA NA
6 Morocco NA NA NA NA NA NA NA NA
# ℹ 67 more variables: `1956.0` <dbl>, `1957.0` <dbl>, `1958.0` <dbl>,
# `1959.0` <dbl>, `1960.0` <dbl>, `1961.0` <dbl>, `1962.0` <dbl>,
# `1963.0` <dbl>, `1964.0` <dbl>, `1965.0` <dbl>, `1966.0` <dbl>,
# `1967.0` <dbl>, `1968.0` <dbl>, `1969.0` <dbl>, `1970.0` <dbl>,
# `1971.0` <dbl>, `1972.0` <dbl>, `1973.0` <dbl>, `1974.0` <dbl>,
# `1975.0` <dbl>, `1976.0` <dbl>, `1977.0` <dbl>, `1978.0` <dbl>,
# `1979.0` <dbl>, `1980.0` <dbl>, `1981.0` <dbl>, `1982.0` <dbl>, …pandasとpolarsはdrop()メソッドで変数を除外します。
Python (pandas)
Country 1949 1950 ... 2020 2021 2022
0 NaN NaN NaN ... NaN NaN NaN
1 Africa NaN NaN ... NaN NaN NaN
2 North Africa NaN NaN ... NaN NaN NaN
3 Algeria NaN NaN ... 9708.27744 9112.461105 9145.810174
4 Libya NaN NaN ... NaN NaN NaN
[5 rows x 75 columns]Python (polars)
| Country | 1949 | 1950 | 1951 | 1952 | 1953 | 1954 | 1955 | 1956 | 1957 | 1958 | 1959 | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | 1966 | 1967 | 1968 | 1969 | 1970 | 1971 | 1972 | 1973 | 1974 | 1975 | 1976 | 1977 | 1978 | 1979 | 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| str | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 |
| "Africa" | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| "North Africa" | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| "Algeria" | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | 234.875985 | 219.434678 | 215.133118 | 208.22094 | 215.742463 | 413.599801 | 461.022683 | 642.532765 | 560.729351 | 607.406682 | 600.773471 | 683.327939 | 607.328128 | 701.198007 | 704.831389 | 661.921863 | 620.079659 | 610.18241 | 622.034094 | 615.542127 | 601.651385 | 642.72115 | 657.986141 | 1101.032432 | 1183.864801 | 1440.243493 | 1395.429481 | 1588.840569 | 1910.994943 | 2021.120506 | 2133.027701 | 2475.100274 | 2709.025608 | 2768.30774 | 2708.645105 | 3080.937162 | 3225.387723 | 3306.186349 | 3879.058547 | 4519.638056 | 4908.797561 | 5194.999271 | 7434.910242 | 7823.704814 | 8450.873651 | 9732.621963 | 10182.147187 | 10212.538248 | 9671.777933 | 9275.706188 | 10006.914126 | 9773.554762 | 9112.461105 | 8776.364725 |
| "Libya" | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null | 62.239411 | 75.739505 | 135.605176 | 171.736926 | 205.401564 | 280.364831 | 501.713486 | 517.782969 | 399.804189 | 496.86425 | 660.244648 | 403.379454 | 433.595285 | 599.712512 | 705.411019 | 877.90173 | 1006.758017 | 469.762633 | 542.251381 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | 528.148467 | 595.753213 | 460.005767 | 492.339926 | 481.663213 | 619.030119 | 770.484367 | 1006.128971 | 991.116581 | 872.043438 | 820.739134 | 1240.400997 | null | null | null | 2691.266837 | 3509.174752 | 3246.886855 | null | null | null | null | null | null | null | null |
| "Morocco" | null | null | null | null | null | null | null | 119.561947 | 174.29616 | 231.988959 | 270.419973 | 269.797363 | 307.693292 | 326.567713 | 429.706446 | 386.061343 | 336.729958 | 365.821285 | 381.660589 | 491.01178 | 445.838272 | 460.68119 | 552.386269 | 610.999174 | 694.413605 | 818.31678 | 1201.617167 | 1686.646799 | 1934.233958 | 1722.805411 | 1726.670724 | 1987.294925 | 2025.512311 | 2098.786842 | 1527.477606 | 1372.987541 | 1966.91535 | 1721.964873 | 1722.974496 | 1859.410193 | 2010.669934 | 1974.55245 | 2073.654577 | 2057.185887 | 2170.432946 | 2228.159258 | 2052.130321 | 2046.648979 | 2143.497749 | 2169.0585 | 1837.788653 | 1390.760784 | 2516.231872 | 2394.040085 | 2535.872578 | 2464.704546 | 2557.771063 | 2582.189542 | 2659.230192 | 2966.11034 | 3168.016273 | 3390.448538 | 3415.165311 | 3660.78936 | 4182.250761 | 4146.897151 | 3828.72905 | 3852.059058 | 3965.368975 | 3993.067756 | 4076.773137 | 5225.571603 | 5378.366535 | 5368.334058 |
13.4 観察の選択
これまでは変数の操作について見てきましたが、次は観察の選択を学びます。つまり、データに含まれる観察の一部だけを取り出して分析する状況を考えます。

13.4.1 不等号による選択
例えば、Polityのデータのうち、第2次世界大戦後のデータを取り出したいとします。
# A tibble: 9,952 × 37
p5 cyear ccode scode country year flag fragment democ autoc polity
<dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 7001946 700 AFG Afghanistan 1946 0 NA 0 10 -10
2 0 7001947 700 AFG Afghanistan 1947 0 NA 0 10 -10
3 0 7001948 700 AFG Afghanistan 1948 0 NA 0 10 -10
4 0 7001949 700 AFG Afghanistan 1949 0 NA 0 10 -10
5 0 7001950 700 AFG Afghanistan 1950 0 NA 0 10 -10
6 0 7001951 700 AFG Afghanistan 1951 0 NA 0 10 -10
7 0 7001952 700 AFG Afghanistan 1952 0 NA 0 10 -10
8 0 7001953 700 AFG Afghanistan 1953 0 NA 0 10 -10
9 0 7001954 700 AFG Afghanistan 1954 0 NA 0 10 -10
10 0 7001955 700 AFG Afghanistan 1955 0 NA 0 10 -10
# ℹ 9,942 more rows
# ℹ 26 more variables: polity2 <dbl>, durable <dbl>, xrreg <dbl>, xrcomp <dbl>,
# xropen <dbl>, xconst <dbl>, parreg <dbl>, parcomp <dbl>, exrec <dbl>,
# exconst <dbl>, polcomp <dbl>, prior <dbl>, emonth <dbl>, eday <dbl>,
# eyear <dbl>, eprec <dbl>, interim <dbl>, bmonth <dbl>, bday <dbl>,
# byear <dbl>, bprec <dbl>, post <dbl>, change <dbl>, d5 <dbl>, sf <dbl>,
# regtrans <dbl># A tibble: 6 × 37
p5 cyear ccode scode country year flag fragment democ autoc polity
<dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 7001800 700 AFG Afghanistan 1800 0 NA 1 7 -6
2 0 7001801 700 AFG Afghanistan 1801 0 NA 1 7 -6
3 0 7001802 700 AFG Afghanistan 1802 0 NA 1 7 -6
4 0 7001803 700 AFG Afghanistan 1803 0 NA 1 7 -6
5 0 7001804 700 AFG Afghanistan 1804 0 NA 1 7 -6
6 0 7001805 700 AFG Afghanistan 1805 0 NA 1 7 -6
# ℹ 26 more variables: polity2 <dbl>, durable <dbl>, xrreg <dbl>, xrcomp <dbl>,
# xropen <dbl>, xconst <dbl>, parreg <dbl>, parcomp <dbl>, exrec <dbl>,
# exconst <dbl>, polcomp <dbl>, prior <dbl>, emonth <dbl>, eday <dbl>,
# eyear <dbl>, eprec <dbl>, interim <dbl>, bmonth <dbl>, bday <dbl>,
# byear <dbl>, bprec <dbl>, post <dbl>, change <dbl>, d5 <dbl>, sf <dbl>,
# regtrans <dbl># A tibble: 6 × 37
p5 cyear ccode scode country year flag fragment democ autoc polity
<dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 7001946 700 AFG Afghanistan 1946 0 NA 0 10 -10
2 0 7001947 700 AFG Afghanistan 1947 0 NA 0 10 -10
3 0 7001948 700 AFG Afghanistan 1948 0 NA 0 10 -10
4 0 7001949 700 AFG Afghanistan 1949 0 NA 0 10 -10
5 0 7001950 700 AFG Afghanistan 1950 0 NA 0 10 -10
6 0 7001951 700 AFG Afghanistan 1951 0 NA 0 10 -10
# ℹ 26 more variables: polity2 <dbl>, durable <dbl>, xrreg <dbl>, xrcomp <dbl>,
# xropen <dbl>, xconst <dbl>, parreg <dbl>, parcomp <dbl>, exrec <dbl>,
# exconst <dbl>, polcomp <dbl>, prior <dbl>, emonth <dbl>, eday <dbl>,
# eyear <dbl>, eprec <dbl>, interim <dbl>, bmonth <dbl>, bday <dbl>,
# byear <dbl>, bprec <dbl>, post <dbl>, change <dbl>, d5 <dbl>, sf <dbl>,
# regtrans <dbl>Python (pandas)
p5 cyear ccode scode country ... post change d5 sf regtrans
146 0 7001946 700 AFG Afghanistan ... NaN NaN NaN NaN NaN
147 0 7001947 700 AFG Afghanistan ... NaN NaN NaN NaN NaN
148 0 7001948 700 AFG Afghanistan ... NaN NaN NaN NaN NaN
149 0 7001949 700 AFG Afghanistan ... NaN NaN NaN NaN NaN
150 0 7001950 700 AFG Afghanistan ... NaN NaN NaN NaN NaN
[5 rows x 37 columns]Python (polars)
| p5 | cyear | ccode | scode | country | year | flag | fragment | democ | autoc | polity | polity2 | durable | xrreg | xrcomp | xropen | xconst | parreg | parcomp | exrec | exconst | polcomp | prior | emonth | eday | eyear | eprec | interim | bmonth | bday | byear | bprec | post | change | d5 | sf | regtrans |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| i64 | i64 | i64 | str | str | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 |
| 0 | 7001946 | 700 | "AFG" | "Afghanistan" | 1946 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| 0 | 7001947 | 700 | "AFG" | "Afghanistan" | 1947 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| 0 | 7001948 | 700 | "AFG" | "Afghanistan" | 1948 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| 0 | 7001949 | 700 | "AFG" | "Afghanistan" | 1949 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| 0 | 7001950 | 700 | "AFG" | "Afghanistan" | 1950 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
ここでも共通点が見えてきます。tidyverseとpolarsではfilter()の中に条件式を入れます。一方、Rの標準関数とpandasでは,の左側に条件式を入れます。
<や>は通常の意味通り、使うことができます。- 等号も含む場合は
<=や>=とします。
13.4.2 等号による選択
次に、日本だけのデータを取り出したいと思います。=ではなく==(=が2つ)である点に注意してください。
# A tibble: 219 × 37
p5 cyear ccode scode country year flag fragment democ autoc polity
<dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 7401800 740 JPN Japan 1800 0 NA 0 10 -10
2 0 7401801 740 JPN Japan 1801 0 NA 0 10 -10
3 0 7401802 740 JPN Japan 1802 0 NA 0 10 -10
4 0 7401803 740 JPN Japan 1803 0 NA 0 10 -10
5 0 7401804 740 JPN Japan 1804 0 NA 0 10 -10
6 0 7401805 740 JPN Japan 1805 0 NA 0 10 -10
7 0 7401806 740 JPN Japan 1806 0 NA 0 10 -10
8 0 7401807 740 JPN Japan 1807 0 NA 0 10 -10
9 0 7401808 740 JPN Japan 1808 0 NA 0 10 -10
10 0 7401809 740 JPN Japan 1809 0 NA 0 10 -10
# ℹ 209 more rows
# ℹ 26 more variables: polity2 <dbl>, durable <dbl>, xrreg <dbl>, xrcomp <dbl>,
# xropen <dbl>, xconst <dbl>, parreg <dbl>, parcomp <dbl>, exrec <dbl>,
# exconst <dbl>, polcomp <dbl>, prior <dbl>, emonth <dbl>, eday <dbl>,
# eyear <dbl>, eprec <dbl>, interim <dbl>, bmonth <dbl>, bday <dbl>,
# byear <dbl>, bprec <dbl>, post <dbl>, change <dbl>, d5 <dbl>, sf <dbl>,
# regtrans <dbl># A tibble: 6 × 37
p5 cyear ccode scode country year flag fragment democ autoc polity
<dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 7001800 700 AFG Afghanistan 1800 0 NA 1 7 -6
2 0 7001801 700 AFG Afghanistan 1801 0 NA 1 7 -6
3 0 7001802 700 AFG Afghanistan 1802 0 NA 1 7 -6
4 0 7001803 700 AFG Afghanistan 1803 0 NA 1 7 -6
5 0 7001804 700 AFG Afghanistan 1804 0 NA 1 7 -6
6 0 7001805 700 AFG Afghanistan 1805 0 NA 1 7 -6
# ℹ 26 more variables: polity2 <dbl>, durable <dbl>, xrreg <dbl>, xrcomp <dbl>,
# xropen <dbl>, xconst <dbl>, parreg <dbl>, parcomp <dbl>, exrec <dbl>,
# exconst <dbl>, polcomp <dbl>, prior <dbl>, emonth <dbl>, eday <dbl>,
# eyear <dbl>, eprec <dbl>, interim <dbl>, bmonth <dbl>, bday <dbl>,
# byear <dbl>, bprec <dbl>, post <dbl>, change <dbl>, d5 <dbl>, sf <dbl>,
# regtrans <dbl>R (tidyverse)
# A tibble: 6 × 37
p5 cyear ccode scode country year flag fragment democ autoc polity
<dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 7401800 740 JPN Japan 1800 0 NA 0 10 -10
2 0 7401801 740 JPN Japan 1801 0 NA 0 10 -10
3 0 7401802 740 JPN Japan 1802 0 NA 0 10 -10
4 0 7401803 740 JPN Japan 1803 0 NA 0 10 -10
5 0 7401804 740 JPN Japan 1804 0 NA 0 10 -10
6 0 7401805 740 JPN Japan 1805 0 NA 0 10 -10
# ℹ 26 more variables: polity2 <dbl>, durable <dbl>, xrreg <dbl>, xrcomp <dbl>,
# xropen <dbl>, xconst <dbl>, parreg <dbl>, parcomp <dbl>, exrec <dbl>,
# exconst <dbl>, polcomp <dbl>, prior <dbl>, emonth <dbl>, eday <dbl>,
# eyear <dbl>, eprec <dbl>, interim <dbl>, bmonth <dbl>, bday <dbl>,
# byear <dbl>, bprec <dbl>, post <dbl>, change <dbl>, d5 <dbl>, sf <dbl>,
# regtrans <dbl>Python (pandas)
p5 cyear ccode scode country ... post change d5 sf regtrans
7921 0 7401800 740 JPN Japan ... -10.0 88.0 1.0 NaN NaN
7922 0 7401801 740 JPN Japan ... NaN NaN NaN NaN NaN
7923 0 7401802 740 JPN Japan ... NaN NaN NaN NaN NaN
7924 0 7401803 740 JPN Japan ... NaN NaN NaN NaN NaN
7925 0 7401804 740 JPN Japan ... NaN NaN NaN NaN NaN
[5 rows x 37 columns]Python (polars)
| p5 | cyear | ccode | scode | country | year | flag | fragment | democ | autoc | polity | polity2 | durable | xrreg | xrcomp | xropen | xconst | parreg | parcomp | exrec | exconst | polcomp | prior | emonth | eday | eyear | eprec | interim | bmonth | bday | byear | bprec | post | change | d5 | sf | regtrans |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| i64 | i64 | i64 | str | str | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 | i64 |
| 0 | 7401800 | 740 | "JPN" | "Japan" | 1800 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | 1 | 1 | 1800 | 1 | -10 | 88 | 1 | null | null |
| 0 | 7401801 | 740 | "JPN" | "Japan" | 1801 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| 0 | 7401802 | 740 | "JPN" | "Japan" | 1802 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| 0 | 7401803 | 740 | "JPN" | "Japan" | 1803 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
| 0 | 7401804 | 740 | "JPN" | "Japan" | 1804 | 0 | null | 0 | 10 | -10 | -10 | null | 3 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 1 | null | null | null | null | null | null | null | null | null | null | null | null | null | null | null |
13.4.3 部分集合による選択
第2次世界大戦後から冷戦終結までのデータを取り出したい場合は、「かつ (and)」を意味する&を使います。
- Pythonではそれぞれの条件部分を
()でくくる必要があります。
なお、次のように範囲を指定することもできます。
13.4.4 和集合による選択
日本と中国のデータを取り出す場合は、「または (or)」を意味する|を使います。
次のように簡単に書くこともできます。
なお、否定を表す場合はRの場合は!を、Pythonの場合は~を条件式の冒頭に付けます。
- RでもPythonでも
==の否定は!=でも構いません。
13.4.5 ユニークなデータの選択
例えば、データフレームに含まれる国名をデータフレームにしたい場合、単に国名の変数だけを取り出すと、いろいろな年のデータも含まれるので重複が生じます。このような場合は、次のようにします。
# A tibble: 6 × 1
country
<chr>
1 Afghanistan
2 Albania
3 Algeria
4 Angola
5 Argentina
6 Armenia Python (pandas)
0 Afghanistan
219 Albania
324 Algeria
381 Angola
425 Argentina
Name: country, dtype: object