デジタル化する社会
技術政策学(データ科学編)
はじめに
日進月歩の分野なので、本章の内容はすぐに古いものになる(or既にそうであるかもしれない)点に注意。
人工知能 (artificial intelligence) とは?


- コンピュータ(機械)が人間のように意思をもって、自律的に認識・判断・行動する?
\(\leadsto\)機械学習について学ぶことで(昨今、話題になっている)人工知能について理解する。
なぜ機械学習 (machine learning) か?
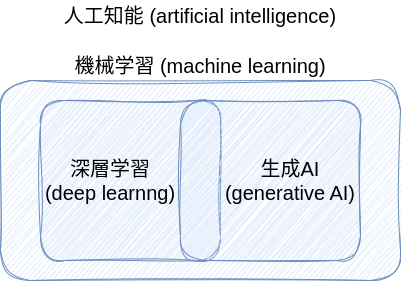
機械学習:データから一定のパターンを機械(パソコン)が学習し、予測をする。
近年の人工知能\(\approx\)機械学習のブレイクスルー
- ビッグデータの利活用
- 深層学習(およびその発展形)の発明
- 豊富な計算資源
\(\leadsto\)特に(我々にとって)重要な1点目と2点目に焦点
1 ビッグデータ
インターネット空間の拡大やセンシング技術の向上(スマートフォン、衛星写真)により、ビッグデータを収集することができる。
- ビッグデータ:人間の様々な活動が粒度の高い(従って大規模な)データとして記録される。
- インターネットはそのようなデータを生み出す最初の空間だったが、最近ではインターネットに限られない。
\(\leadsto\)ビッグデータの特徴は大規模であること自体ではなく、粒度 (granularity) が高い(データが細かい)ことである。
- 多様性 (variery) :国レベルではなく地方自治体、個人レベル
- 小さいレベルのデータから全体を作ることはできるが、その逆ではない。
- 速度 (velocity) :年単位ではなく月単位、分単位
- 一定の間隔や一時的なデータ収集ではなく、always-onが理想である。
- 量 (volume) :多様性と速度の結果としての大規模データ
\(\leadsto\)ビッグデータを解析できる機械学習(特に深層学習)の登場により、ビッグデータの価値が生まれ始めている。
1.1 ビッグではないデータ
伝統的なデータは分析レベルが荒いデータである。
多くの場合、
- 国レベルに集計したり、一部の個人のみを対象
- 毎年、イベントごとなど特定の時点のみを対象
としている。
1.2 地理情報システム
GPS付きスマートフォンのデータにより個人の位置情報がほぼリアルタイムで計測できる。
- 外出者の数や移動経路が分かり、感染症対策に利活用できる。
地理情報システム (geospatial information system: GIS) の発展・普及によって地理空間データの利活用が進んでいる。
人工衛星の写真から経済発展や森林破壊の度合いを測定することができる。
\(\leadsto\)リモート・センシングによりこれまでアクセスできなかったデータを取得できる。
- 統計が怪しい、取ることのできない地域のデータ
- 行政単位よりも細かい地域区分でデータ


通話履歴から個人の(従って地域の)豊かさを予測することができる。
- ルワンダ最大の携帯電話会社の協力を得て分析を行った。

街中にある監視カメラと画像認識技術を組み合わせることで、犯人の迅速な逮捕や犯罪防止に役立っている。
- プライバシーの侵害の懸念はある。
- 中国は監視技術を外国に輸出している。
GISを(無料で)使えるサービスがある。
1.3 企業データ
株式保有のデータを用いて、株式ネットワークのデータを構築することができる。
\(\leadsto\)直接的だけでなく間接的に、どのような株主が、どのような企業を、どの程度接続しているのかが分かる。
- 間接的支配を含めると、中国政府は世界最大の株主である。
- 一般的に販売されている金融商品の約9割が軍事企業や環境破壊企業に繋がっている。
- 「隠れ株主」を探せ:米テスラ、サプライチェーンの「身体検査」
1.4 デジタル・ヒューマニティーズ
人文学(特に歴史学)にデジタル技術を取り入れている分野をデジタル・ヒューマニティ (digital humanity) と呼ぶ。
電子書籍によって大量の書籍を電子的に処理することが可能になった。
- Google Ngram ViewerやNDL Ngram Viewerによって1800年ごろから書籍における単語の頻度を見ることができる。
画像認識の技術を応用して日本史の資料のデジタル化が進んでいる。
2 インターネット空間
21世紀の特徴の1つはインターネット空間の登場と拡大である。
\(\leadsto\)情報通信コストが限りなく下がり、経済活動だけでなく言論空間もオンライン上に構築された。
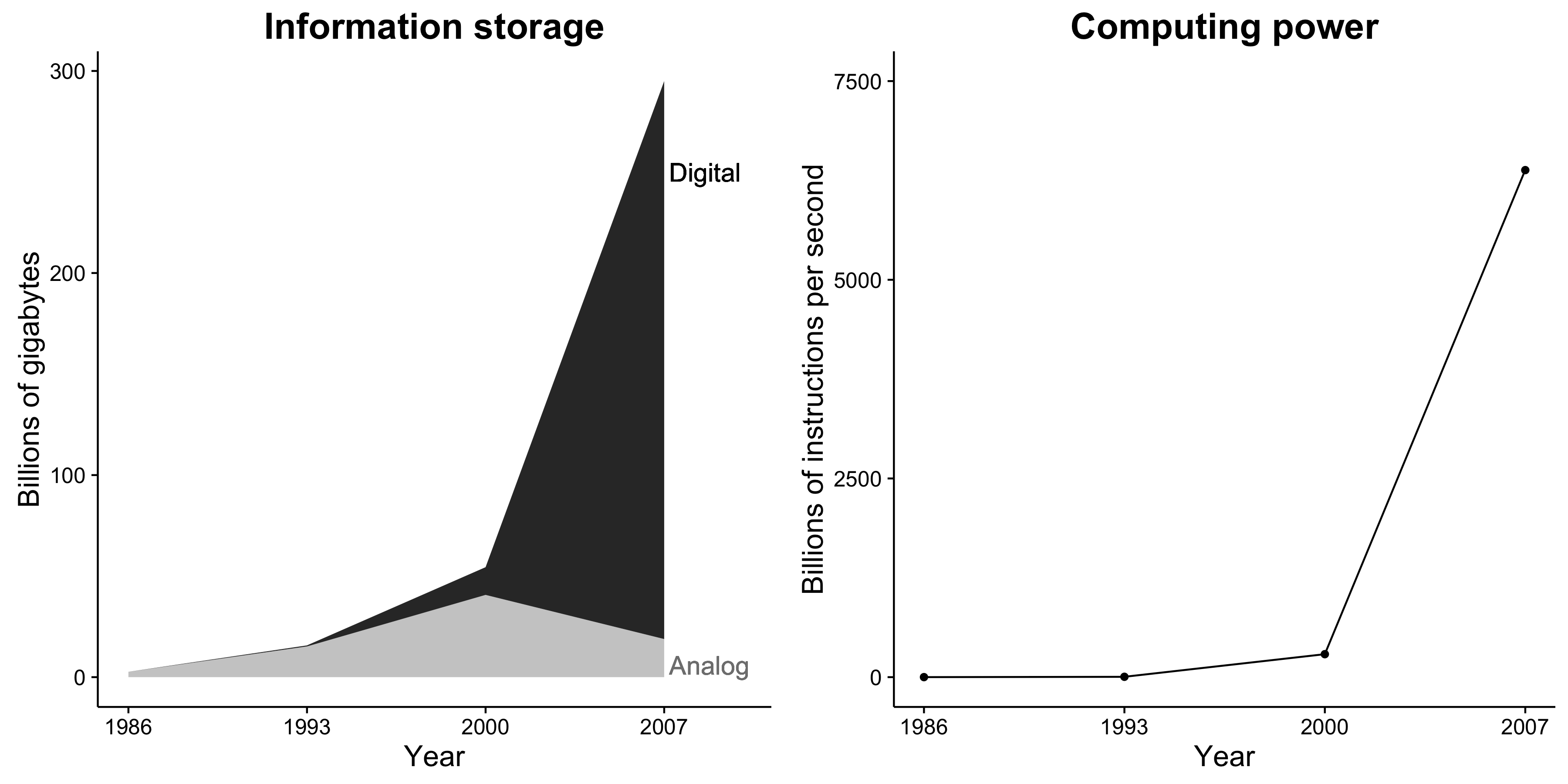
ビッグデータという観点からすると、膨大な量のデータが日々、作られている。
- テキストデータ
- 画像データ
- 音声データ
- 映像データ
\(\leadsto\)人工知能の誕生によって、はじめてビッグデータに価値が生まれ、インターネット空間が(さらに)変容しつつある。
なぜGoogleは強いのか?
- Google Flu Trendsというインフルエンザに関する検索傾向からインフルエンザの感染を予測するサービスがあった(現在は中止)。

- Googleトレンドで検索傾向を調べることができる。
しかも、人々がアノテーション(情報の付加)をしてくれている。
- 商品やお店のレビュー
- 画像のタグ付け(画像つきツイート)、地理情報
2.1 ソーシャル・ネットワーク
デジタル・フットプリント(インターネット上の行動履歴)から個人的属性を予測できる。
\(\leadsto\)個人に焦点を当てた(パーソナライズした)マーケティングを行える。
- インターネットの広告、eコマースにおける推薦
\(\leadsto\)ユーザーは自由に情報を検索して、選択しているつもりでも、表示される情報は誘導されている。
Netflixはデータを公開して予測コンペ (Netflix Prize) を行っていた。
公開されたデータは匿名であるが、視聴履歴から個人を特定することができることが分かる。
- 脱匿名化、再識別などと呼ぶ。
\(\leadsto\)政治信条や性的志向が判明する危険性がある。
SNSは豊富な情報を持つビッグデータである。
- 個人レベル
- always-on
- テキスト、画像と繋がり(ネットワーク)
\(\leadsto\)政治信条や性的志向が暴露されてしまう危険性がある。
- とある研究ではFacebookの「いいね (like) 」を使って個人属性を予測した。

- ケンブリッジ・アナリティカ社がFacebook上で選挙介入を行ったと指摘されている。
2.2 SNS上のコミュニティ
人々は同じ意見を持っている人同士で繋がる傾向をホモフィリーと呼ぶ。
- トランプのフォロワーはクリントンのフォロワーと繋がりにくい。

- 同じ党派性のアカウントをフォロー、リツイートする。
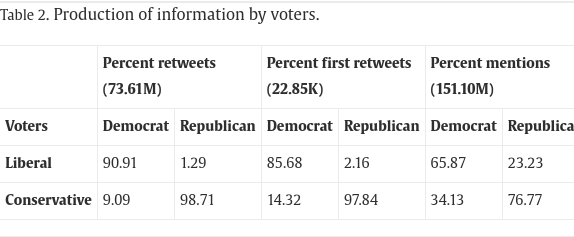
同質的なコミュニティで意見が反射、増幅して信念が強化されるエコー・チェンバーが生じる。
- 人種差別についてリベラルでしか議論されない。
- 移民や銃については両方で議論されているが、繋がってはいない。
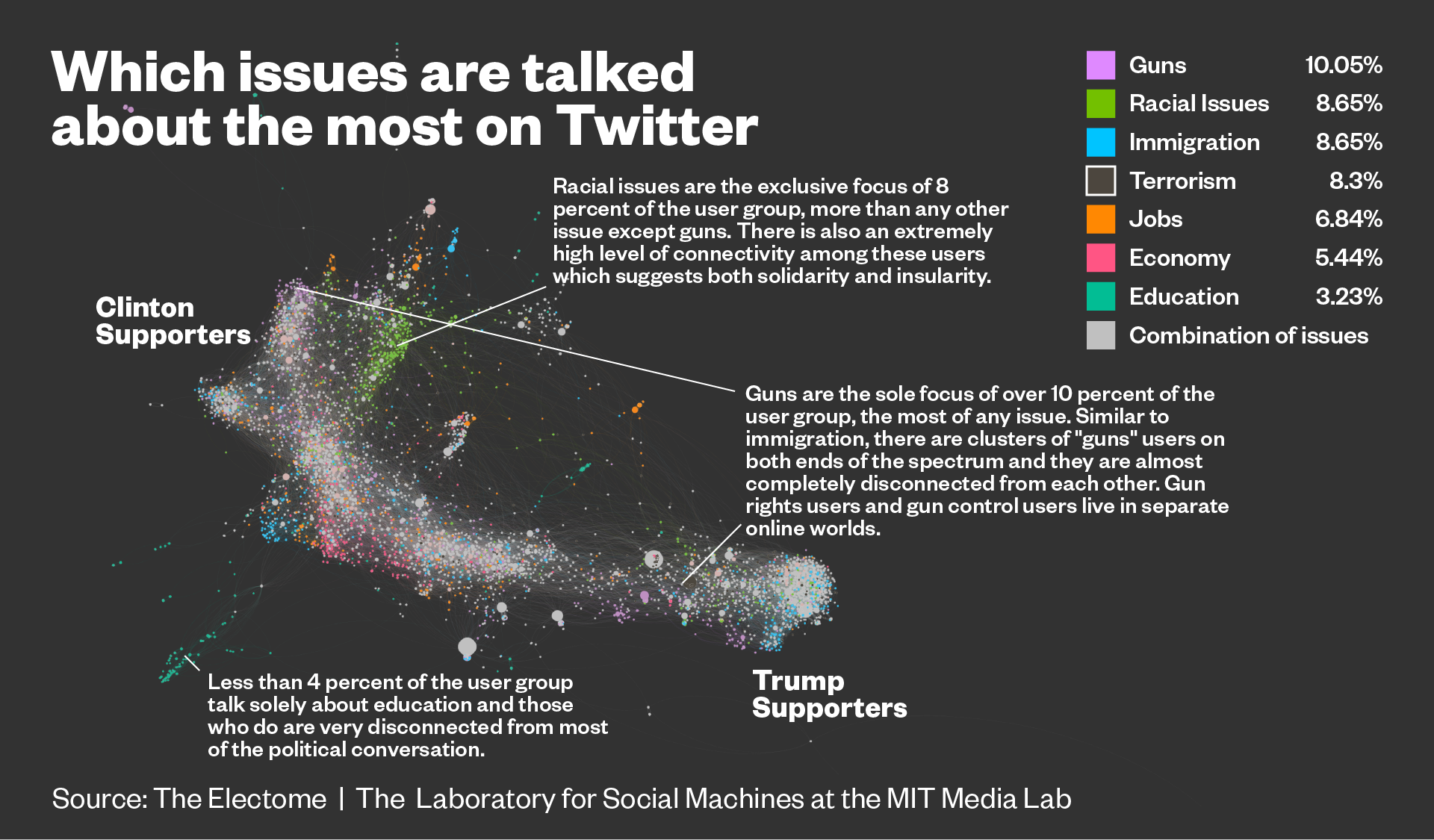
SNSがパーソナライズされる(フォローの推薦)ことで投稿内容やユーザーが限定される。
\(\leadsto\)(本人の意図によらず)見たくない情報がSNS上から除去されるフィルター・バブルができる。

- 共和党支持者は気候変動は嘘であると信じ、民主党支持者は遺伝子組み換え食品を危険だと思っている。
- 教育水準が高ければ、科学的知識を身につけるとは限らない。

ホモフィリーが正しいのだとすれば、SNS上の繋がりから政治的イデオロギーも分かる。
- SNS上を通じて世論や分極化をリアルタイムに観測できる。
- SNS上の情報で個人の政治的傾向が分かってしまう。

2.3 SNSと分極化・分断
分極化 (polarization):社会において意見(特にイデオロギー)が分断し、それぞれ極端になっていく現象
\(\leadsto\)インターネットは分極化を加速させるのか?
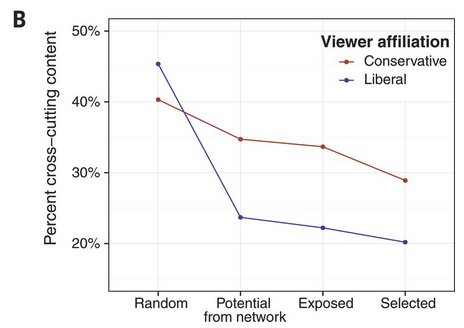
稲増 (2022年, 第5章)によれば、そこまでの影響力は大きくない。
- アルゴリズムによる表示 (exposed) よりも、自身の選択 (selected) の方が異なるイデオロギーの記事にアクセスしにくい(あるいは大差はない)。
- ニュースアグリゲーターよりもSNSなどのほうが多様な意見のサイトにアクセスしやすい。
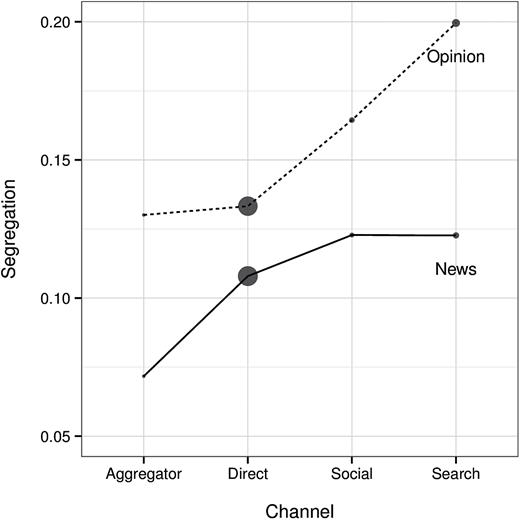
- ニュースアグリゲーターやSNSは異なる意見のサイトにアクセスしやすい。
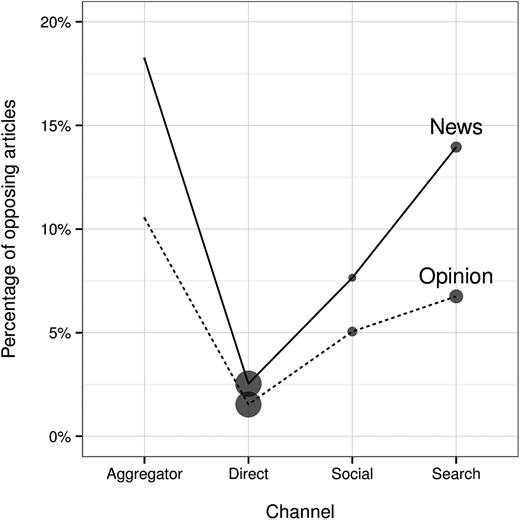
\(\leadsto\)アルゴリズムによる分断よりも、自らの選択?
異なる意見・民族の人との接触は偏見を減らす(Paluck ほか 2019年)。
- 単なる接触だけでは不十分かも?
2.4 中国によるSNS検閲
中国ではTwitterなどは利用できないが、類似のサービスが利用されているが、検閲されているかもしれない。
\(\leadsto\)とある研究によって、情報を隠すという検閲により、隠したい中国政府の意図が分かってしまった。
どうやって検閲を見つけるのか?
- 人力検閲で削除される前にスクレイピングする。
- 実際に中国のSNSアカウントを作り、投稿する。
- 実際に中国のSNSサービスを作り、マニュアルを見る。
自動検閲される確率は(2013年時点では)ほとんどない。

中国で検閲されやすい内容は
- デモや集会に繋がる行動
- 検閲の批判
- ポルノグラフィー
に関するものである。
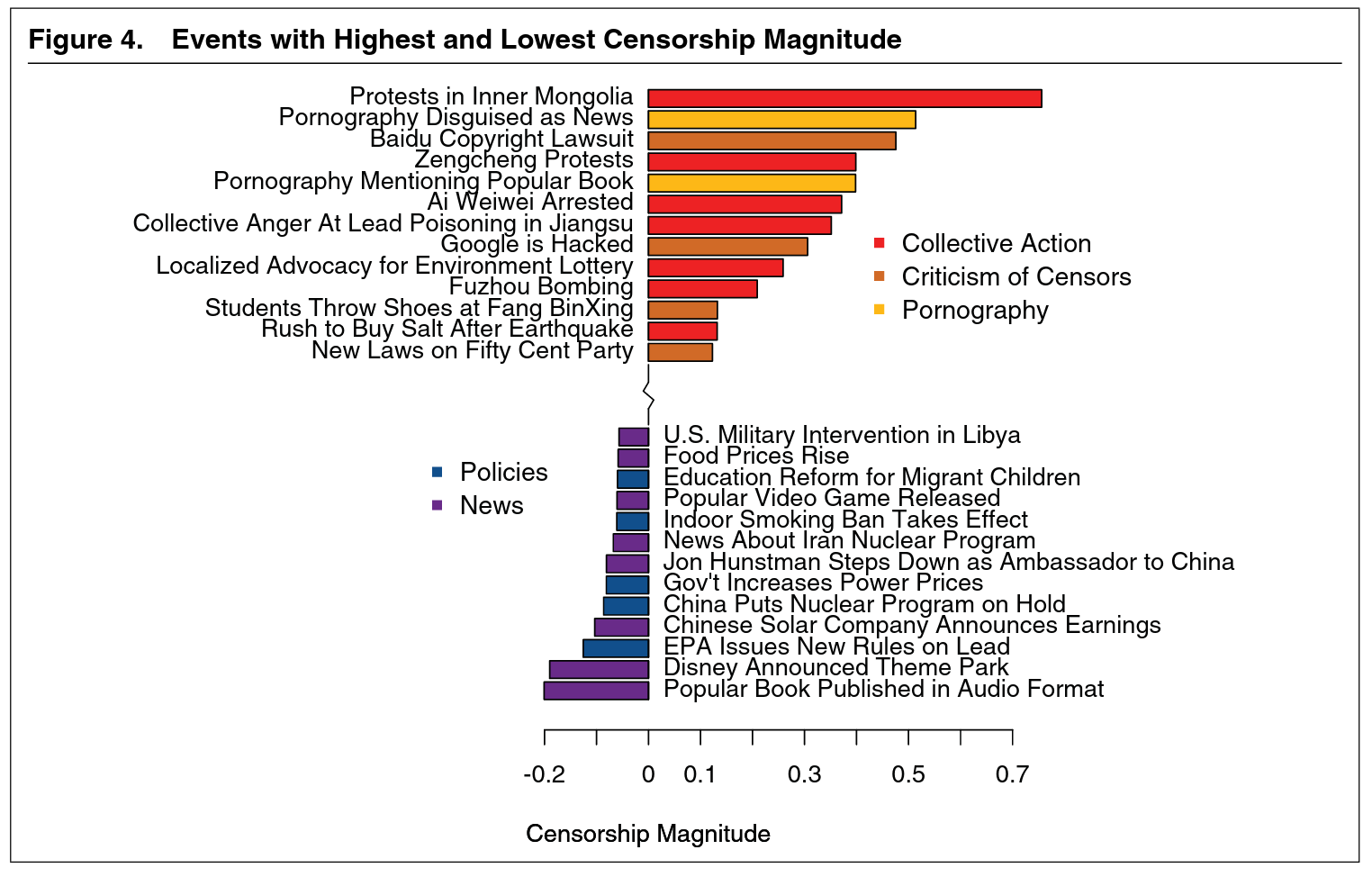
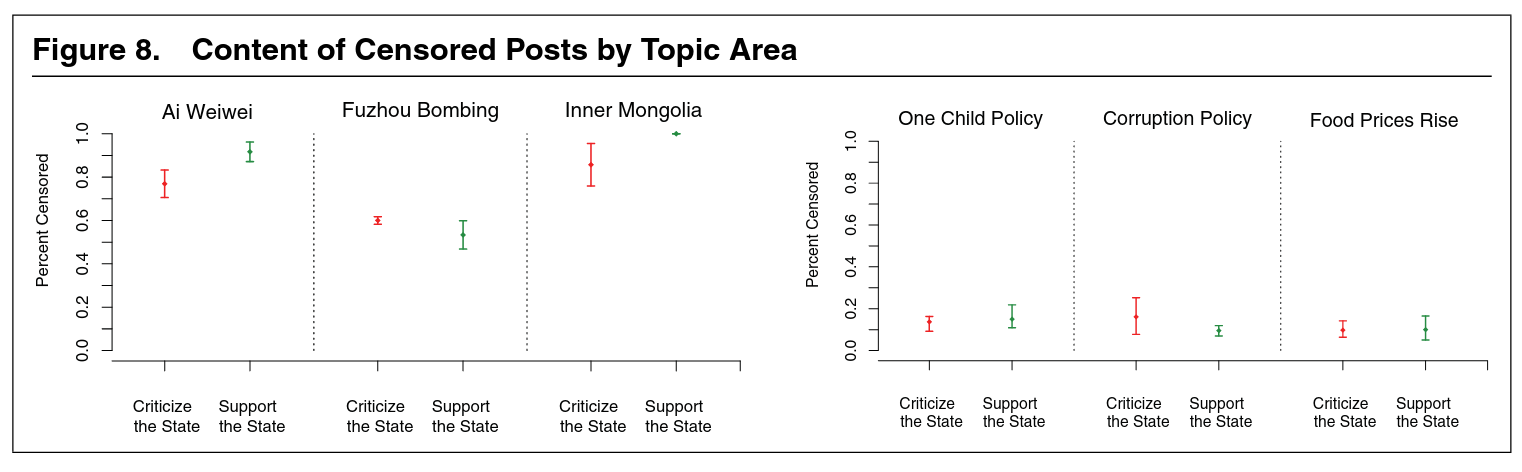
検閲される確率は政府に対して肯定的であるか批判的であるかは「関係がない」。
- 天安門事件に関する投稿だからといって削除されるとは限らない。
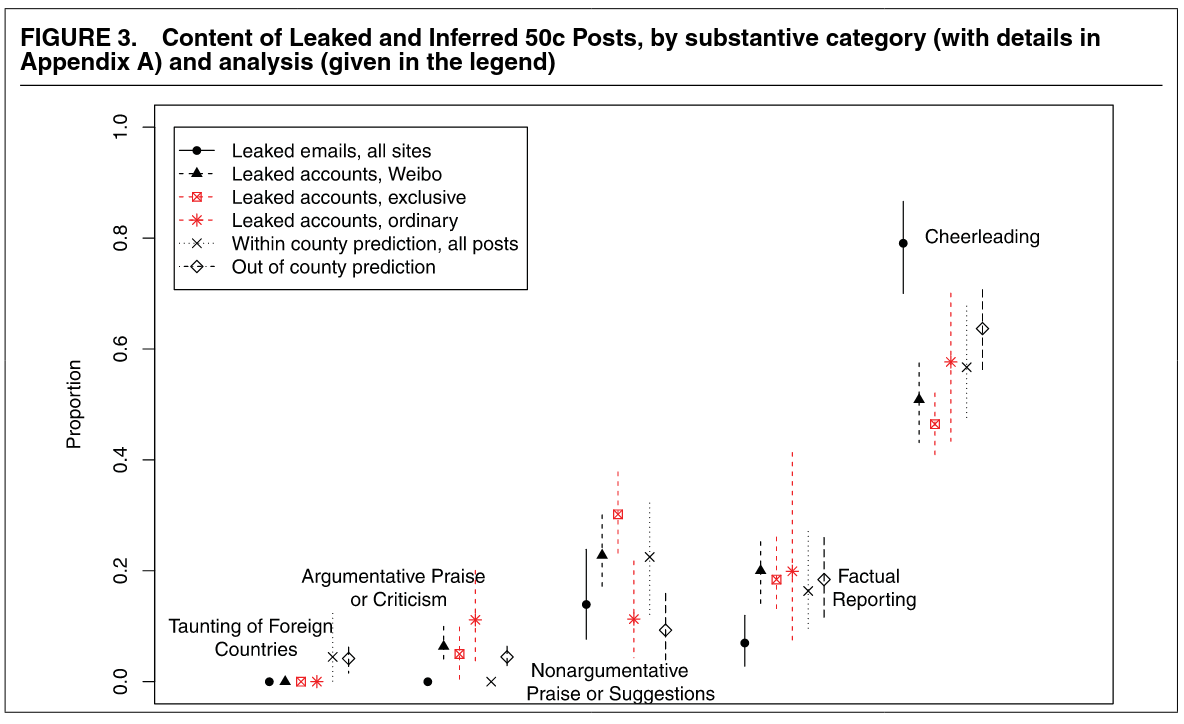
中国のSNSでは五毛党 (50 Cent Party) が世論誘導 (astroturfing) を行っていると考えられている。
- とある地区の五毛党のリストがリークした。
\(\leadsto\)機械学習によって五毛党のアカウントを予測し、それらの投稿の内容も分類できる。
五毛党は協調して投稿している。
五毛党は外国の批判や論争への参加はしていない。
- 愛国心を煽る表現
- 政府の政策の紹介
- 論争的ではない政府の称賛
\(\leadsto\)政府の意見を広めるというより、不都合な情報から目を逸らそうとしているのでは?
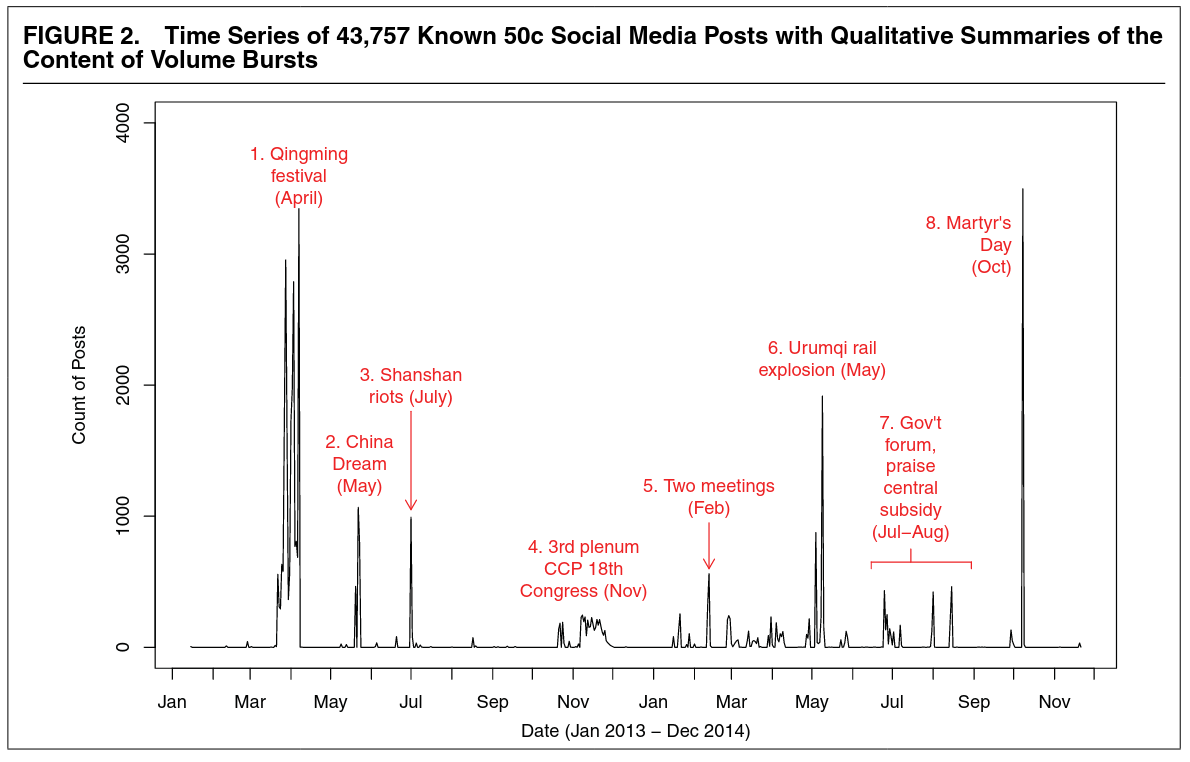
2.5 オンライン実験
A/Bテストとはランダムに異なるウェブサイトを表示し、収益の高いウェブサイトを見つける実験のことである。1
1 実験については統計的因果推論において解説する。
- オバマ元大統領は選挙資金の寄付を受け付けるサイトのデザインでA/Bテストを行い、約6000万ドルの寄付増加に繋がったと言われている。

オンライン上では(しばしば利用者が知らないうちに)実験が行われている。
- Facebookの選挙実験では友人が投票に行ったことを知ると、投票率が上がることが分かった。
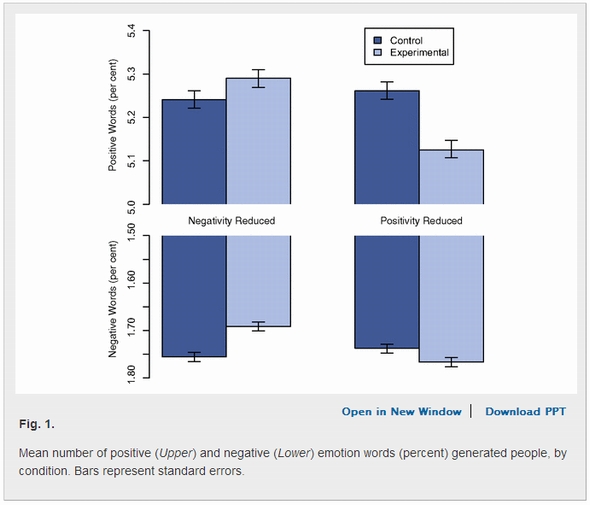
- Facebookの感情実験ではTL上にネガティブな投稿が表示されなくなると、ポジティブな投稿が増える(その逆も然り)ことが分かった。
2.6 影響工作
影響工作 (influence operation):フェイクニュースなどを通じて世論に影響を与えようとする行動
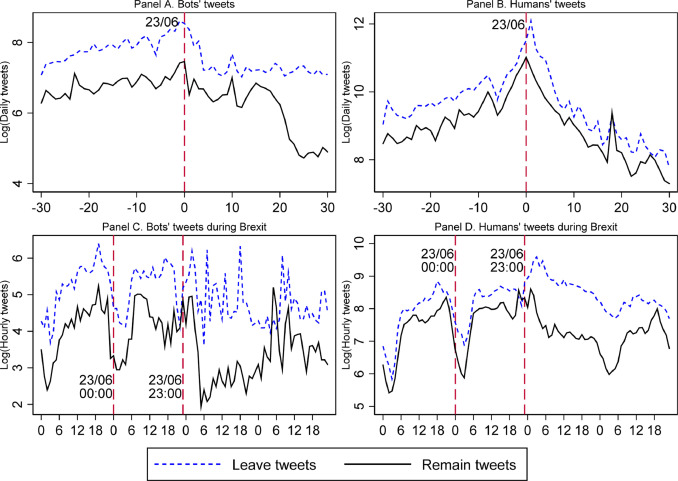
\(\leadsto\)インターネット空間ではボットによる情報提供が容易に(Lazer ほか 2009年; Ferrara ほか 2016年)。
- 2016年のアメリカ大統領選ではトランプ支持のツイートを(特に接戦州で)ボットが共有
- イギリスのEU離脱投票の際にも賛成派と反対派のボットが情報を拡散
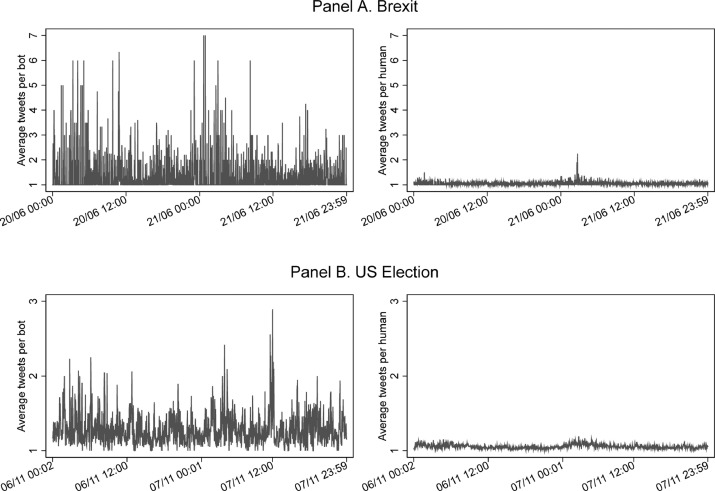
信頼のできないボット(赤い点)が特定のユーザーをリツイートしている。
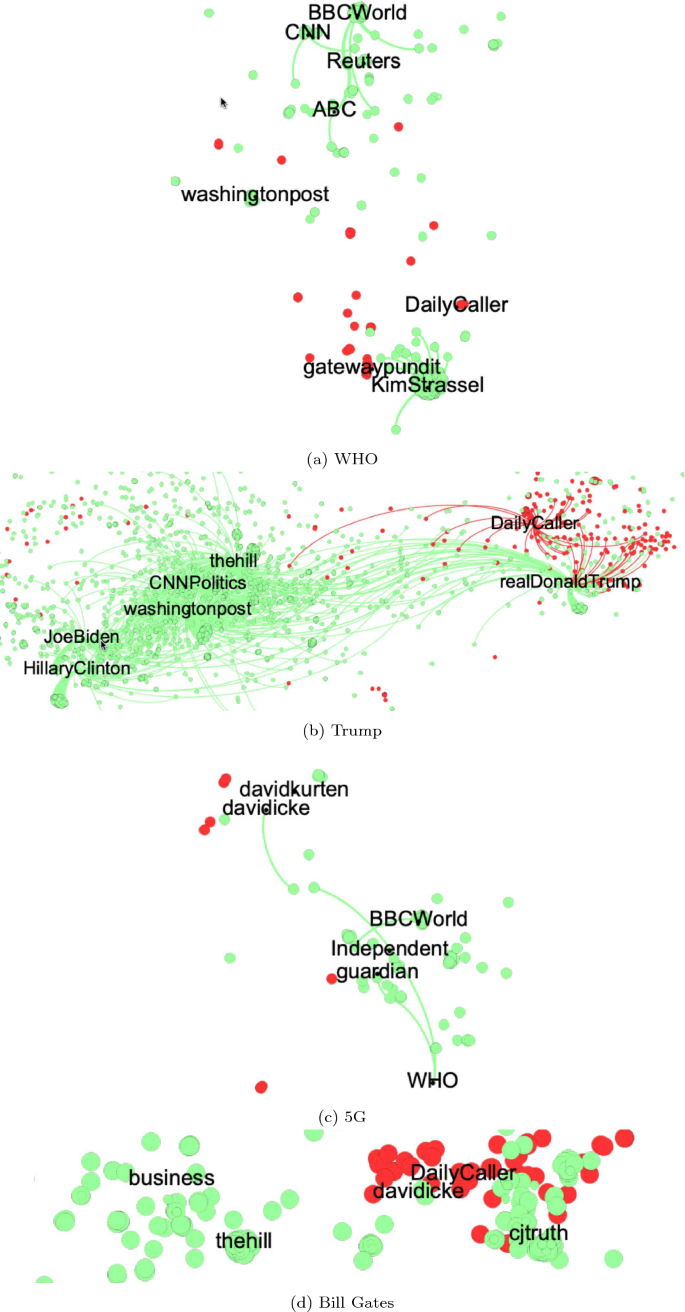
- 信頼のできないボットは陰謀論者をリツイート
- スーパスプレッダーとなるボット
とある研究によれば、フェイクニュースは正しいニュースよりもリツイートされやすく、早く、広く拡散する。
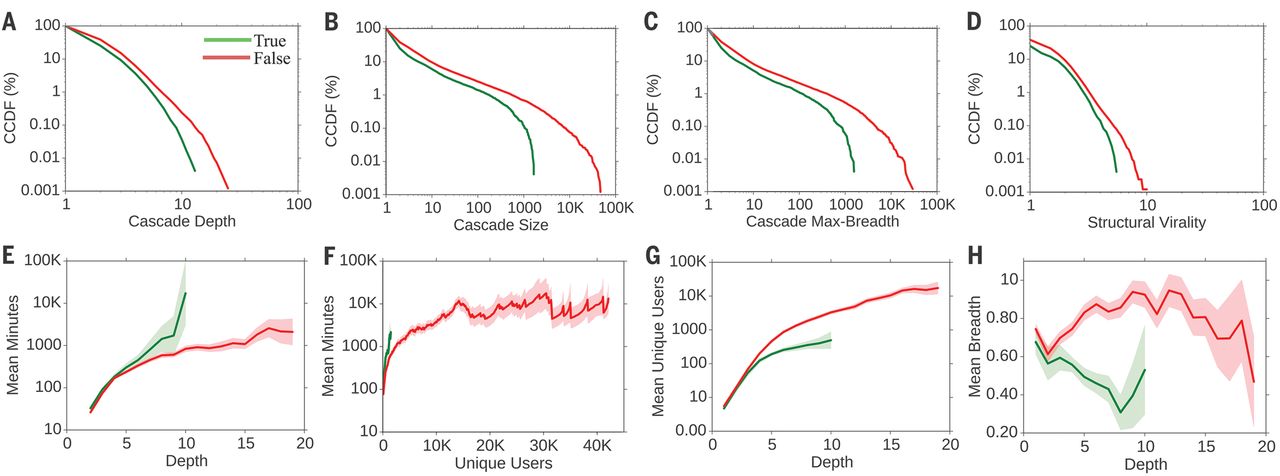
ただし、インターネットを含めてマスメディアの影響を過大評価するべきではない。
- インターネットではない伝統的メディアでも同様の問題は起こっている。
- オフラインでも党派性に従ってニュースを消費している(Gentzkow と Shapiro 2011年; Martin と Yurukoglu 2017年)。
- メディアの効果に関するサーベイとして 稲増 (2022年) を参照。
2.7 新しい戦場
軍事行動や社会活動が情報化 \(\leadsto\)宇宙空間とインターネット空間も戦場?
- 偵察衛星や通信衛星、GPSは軍事行動において必要不可欠
- 社会的インフラへのサイバー攻撃やフェイクニュースの拡散によって社会を混乱させる?
\(\leadsto\)問題は攻撃側をどのように特定するのか、物理的な報復手段が許されるのか
3 資源としてのデータ
機械学習が調理法だとすれば、データは食材と言える。
\(\leadsto\)近年の機械学習の発展(後述)により、データの価値が発見(21世紀の資源と呼ばれることも)
- データそれ自体に価値があるわけではない。
- 適切な調理法(と下ごしらえ)がなければ宝の持ち腐れ。
機械学習において、データの量が多いことは性能の向上に繋がるスケーリング則が発見されている。

\(\leadsto\)資源としてデータは足りるのか?
質の良いテキストデータは近いうちに枯渇する可能性が指摘されている。
- 非デジタル情報のデジタル化?
- ネットユーザーの拡大?
- AI利用者の入力データの利用?